This example is taken from Levy and Lemeshow’s Sampling of Populations.
page 250 simple one-stage cluster sampling
We have added a variable called cons to the data set for use in making the table (shown below). It is often convenient to have a variable with a constant value in your WesVar data file for use in making tables. Although any variable will do, a variable with only one value will make a table with relatively few rows and thus easier to interpret.
In this example, the variable wt1 is used as the weight variable, the variable devlpmnt is used as the VarUnit and the variable nge65 is used as the analysis variable. The jackknife1 (jk1) method of creating the replicate weight is used because we do not have stratification in this design.
The output is given below.
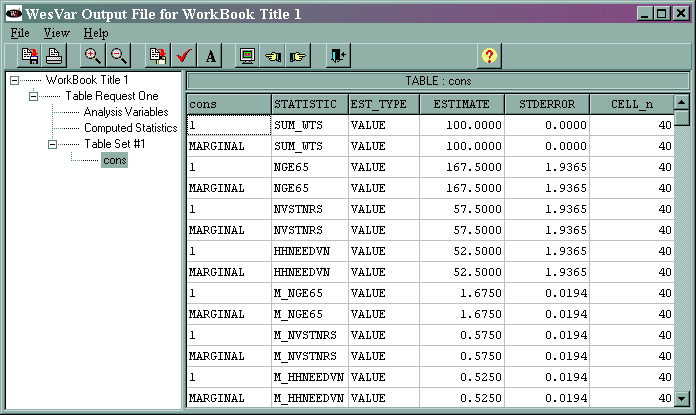
The marginal sum_wts value of 100 is the estimated population total. The marginal nge65 value of 167.5 is the estimated total of the variable nge65, and its standard error is 1.9365. The marginal nvstrnrs value of 57.5 is the estimated total of the variable nvstrnrs, and 1.9365 is its standard error. The marginal value of hhneedvn of 52.5 is the estimated total of the variable hhneedvn, and its standard error is 1.9365. The marginal value of m_nge65 is 1.6750 and this is the estimated mean of the variable nge65. The standard error of this estimate is 0.0194. The rest of the estimated means are found in the same manner.
This example is taken from Lehtonen and Pahkinen’s Practical Methods for Design and Analysis of Complex Surveys.
page 78 Table 3.8 Estimates from a one-stage CLU sample (n = 8); the Province’91 population.
In this example, the variable wt is used as the weight variable, the variable clu is used as the VarUnit and the variable
ue91 is used as the analysis variable.
The output is given below.
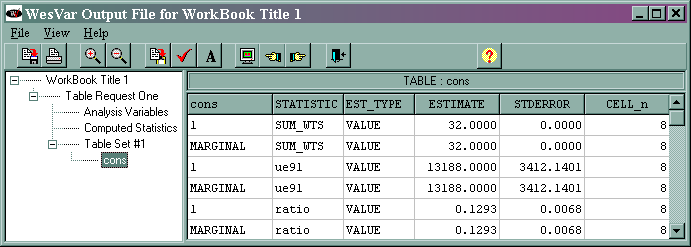
The marginal sum_wts value of 32 is the estimated population total. The marginal ue91 value of 13188 is the estimated total of the variable ue91, and its standard error is 3412.1401. The marginal ratio value of 0.1293 is the estimated ratio of ue91/lab91, and its standard error is 0.0068. The output regarding the median has been omitted. The results from WesVar differ from those given in the text. We suspect that this is due to a difference in the algorithms used by the different statistical packages.