In this chapter we will be using the following centered variables: GndC_verb is iq_verb centered around the grand mean; GrpMC_verb contains the group means of GndC_verb.
Furthermore, we will be creating the following centered variables: GndC_size which is the grand mean centered variable for groupsiz; GndC_ses which is ses centered around the grand mean.
data schools; set 'c:sasmlbook1'; run; *Creating GndC_verb by centering verb_iq around grand mean. ; proc sql; create table schools1 as select *, iq_verb - mean(iq_verb) as GndC_verb from schools; quit; *Creating GrpMC_verb = group means of GndC_verb. ; proc sql; create table schools2 as select *, mean(GndC_verb) as GrpMC_verb from schools1 group by schoolnr; quit;
Table 5.1, p. 71
Random slope model.
proc mixed data=schools2 covtest noitprint noclprint method=ml;
class schoolnr;
model langpost = GndC_verb GrpMC_verb / solution;
random intercept GndC_verb / subject=schoolnr type=un;
run;
<output omitted>
Covariance Parameter Estimates
Standard Z
Cov Parm Subject Estimate Error Value Pr Z
UN(1,1) schoolNR 7.9177 1.3287 5.96 <.0001
UN(2,1) schoolNR -0.8198 0.2914 -2.81 0.0049
UN(2,2) schoolNR 0.1994 0.1003 1.99 0.0234
Residual 41.3525 1.2902 32.05 <.0001
Fit Statistics
-2 Log Likelihood 15213.5
AIC (smaller is better) 15227.5
AICC (smaller is better) 15227.6
BIC (smaller is better) 15247.7
Solution for Fixed Effects
Standard
Effect Estimate Error DF t Value Pr > |t|
Intercept 40.7498 0.2859 129 142.54 <.0001
GndC_verb 2.4588 0.08315 130 29.57 <.0001
GrpMC_verb 1.4052 0.3214 2025 4.37 <.0001
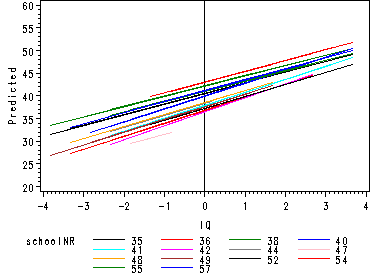
Fig. 5.2, p. 71.
proc mixed data=schools2 covtest noitprint noclprint method=ml dfbw;
class schoolnr;
model langpost = GndC_verb GrpMC_verb / outp=p;
random intercept GndC_verb / subject=schoolnr type=un;
run;
goptions reset=all;
symbol i=j r=24;
axis1 order=(-4 to 4 by 1) label=('IQ');
axis2 order=(20 to 60 by 5) label=(a=90 'Predicted');
proc gplot data=p;
where schoolnr >= 35 and schoolnr < 60;
plot pred*GndC_verb = schoolnr / vaxis=axis2 haxis=axis1 href=0 ;
run;
quit;
Creating GndC_size which is the group centered version of groupsiz. Then we use a proc means to validate that the new variable ranges from -18 to +14 as described in the book, p. 74.
data schools2;
set schools2;
GndC_size = groupsiz - 23.1;
run;
proc means data=schools2;
var GndC_size;
run;
The MEANS Procedure
Analysis Variable : GrpC_size
N Mean Std Dev Minimum Maximum
--------------------------------------------------------------------
2287 0.000568430 7.2985596 -18.1000000 13.9000000
--------------------------------------------------------------------
Table 5.2, p. 75.
Random slopes and cross-level interaction model.
Note: GndC_size corresponds to the variable called z2 in the book.
proc mixed data=schools2 covtest noclprint noitprint method=ml dfbw;
class schoolnr;
model langpost = GndC_verb GrpMC_verb GndC_size GndC_size*GndC_verb / solution;
random intercept GndC_verb / subject=schoolnr type=un;
run;
<output omitted>
Covariance Parameter Estimates
Standard Z
Cov Parm Subject Estimate Error Value Pr Z
UN(1,1) schoolNR 7.6656 1.2910 5.94 <.0001
UN(2,1) schoolNR -0.7674 0.2784 -2.76 0.0058
UN(2,2) schoolNR 0.1772 0.09570 1.85 0.0320
Residual 41.3634 1.2897 32.07 <.0001
Fit Statistics
-2 Log Likelihood 15208.4
AIC (smaller is better) 15226.4
AICC (smaller is better) 15226.5
BIC (smaller is better) 15252.3
Solution for Fixed Effects
Standard
Effect Estimate Error DF t Value Pr > |t|
Intercept 40.8933 0.2922 129 139.97 <.0001
GndC_verb 2.4432 0.08223 2153 29.71 <.0001
GrpMC_verb 1.2462 0.3261 129 3.82 0.0002
GrpC_size 0.05744 0.03687 2153 1.56 0.1194
GndC_verb*GrpC_size -0.02171 0.01090 2153 -1.99 0.0465
Creating the variable GndC_ses.
proc sql; create table schools3 as select *, ses - mean(ses) as GndC_ses from schools2; quit;
Table 5.3, p. 77
Large model with random slopes and many, many fixed effects.
data temp;
set schools3;
by schoolnr;
if first.schoolnr;
keep schoolnr mixedgra;
run;
proc freq data=temp;
tables mixedgra;
run;
Cumulative Cumulative
mixedgra Frequency Percent Frequency Percent
-------------------------------------------------------------
0 77 58.78 77 58.78
1 54 41.22 131 100.00
* GndC_verb is the grand-mean centered iq_verb, level-1 variable;
* mixedgra is COMB , level-2 variable;
* GndC_ses is the grand-mean centered ses, level-1 variable;
* GndC_size is the grand-mean centered group size, level-2 variable;
* GrpMC_verb is the group-mean iq_verb, level-2 variable;
proc mixed data=schools3 covtest method=ml;
class schoolnr;
model langpost = GndC_verb GndC_ses
GrpMC_verb GndC_size mixedgra
GndC_verb*GrpMC_verb GndC_verb*GndC_size GndC_verb*mixedgra
GndC_ses*GrpMC_verb GndC_ses*GndC_size GndC_ses*mixedgra
/ solution ddfm=bw;
random intercept GndC_verb / subject=schoolnr type=un ;
run;
Covariance Parameter Estimates
Standard Z
Cov Parm Subject Estimate Error Value Pr Z
UN(1,1) schoolNR 7.4544 1.2451 5.99 <.0001
UN(2,1) schoolNR -0.6354 0.2545 -2.50 0.0125
UN(2,2) schoolNR 0.1098 0.08136 1.35 0.0885
Residual 39.3668 1.2269 32.09 <.0001
Fit Statistics
-2 Log Likelihood 15089.1
AIC (smaller is better) 15121.1
AICC (smaller is better) 15121.3
BIC (smaller is better) 15167.1
Solution for Fixed Effects
Standard
Effect Estimate Error DF t Value Pr > |t|
Intercept 41.5105 0.3669 129 113.13 <.0001
GndC_verb 2.1251 0.1022 2146 20.80 <.0001
GndC_ses 0.1536 0.02009 2146 7.64 <.0001
GrpMC_verb 0.8327 0.3253 129 2.56 0.0116
GndC_size -0.05671 0.05077 2146 -1.12 0.2641
mixedgra -1.9361 0.7982 2146 -2.43 0.0154
GndC_verb*GrpMC_verb -0.04861 0.08159 2146 -0.60 0.5513
GndC_verb*GndC_size -0.00081 0.01512 2146 -0.05 0.9571
GndC_verb*mixedgra 0.3744 0.2428 2146 1.54 0.1232
GndC_ses*GrpMC_verb -0.01995 0.01881 2146 -1.06 0.2889
GndC_ses*GndC_size -0.00082 0.002886 2146 -0.28 0.7763
GndC_ses*mixedgra 0.01692 0.04597 2146 0.37 0.7129
Table 5.4, p. 78
The model including random slope and many fixed effects which is more parsimonious than the model in table 5.3.
proc mixed data=schools3 covtest noclprint noitprint method=ml dfbw;
class schoolnr;
model langpost = GndC_verb GndC_ses GrpMC_verb mixedgra GndC_verb*mixedgra / solution;
random intercept GndC_verb / subject=schoolnr type=un;
run;
<output omitted>
Covariance Parameter Estimates
Standard Z
Cov Parm Subject Estimate Error Value Pr Z
UN(1,1) schoolNR 7.5574 1.2562 6.02 <.0001
UN(2,1) schoolNR -0.5890 0.2587 -2.28 0.0228
UN(2,2) schoolNR 0.1277 0.08389 1.52 0.0640
Residual 39.3402 1.2253 32.11 <.0001
Fit Statistics
-2 Log Likelihood 15093.4
AIC (smaller is better) 15113.4
AICC (smaller is better) 15113.5
BIC (smaller is better) 15142.1
Solution for Fixed Effects
Standard
Effect Estimate Error DF t Value Pr > |t|
Intercept 41.3213 0.3490 129 118.40 <.0001
GndC_verb 2.1134 0.09245 2152 22.86 <.0001
GndC_ses 0.1555 0.01464 2152 10.63 <.0001
GrpMC_verb 0.8754 0.3237 129 2.70 0.0078
mixedgra -1.3961 0.5743 2152 -2.43 0.0151
GndC_verb*mixedgra 0.4472 0.1701 2152 2.63 0.0086