Suppose that you have a group of people. Each person is given his or her own unique id number. Next, one by one, you ask each person to pick a partner. For each person, you write down his or her id number in one column, and the id number of the partner in a second column. So, the first person picks a partner, and then both people rejoin the group. Then the next person selects a partner. Some people will select the person who had selected them as a partner, while others will select a new person to be their partner. A small, example data set might look like the one below.
110 210 514 856 210 110 210 111 693 246
Now suppose that you want to find all of the unique pairs of people. You will notice that the third case contains the same two person id numbers as the first case. Hence, the third case should be flagged as a duplicate. How can we do this in SPSS?
First, we are going to input the data as string variables (sid1 and sid2), and then make numeric copies of them (nid1 and nid2). (Of course, you could input the data as numeric variables and then make string copies of them.) Next, we are going to concatenate the string variables in two ways. Because we are concatenating the variables, they need to be strings. First, we will concatenate them such that the smallest id number is first. Next, we will concatenate them such that the largest id number is first. We need the numeric version of the variables to determine which is the smallest and which is the largest of the two variables. Once we have done this, we can sort the new variable created by the concatenation and create the flag variable. Below is the syntax for these steps.
data list list / sid1 (A3) sid2 (A3). begin data. 110 210 514 856 210 110 210 111 693 246 end data. recode sid1 (convert) into nid1. recode sid2 (convert) into nid2. string pairid (A6). if (nid1 lt nid2) pairid = concat(sid1, sid2). if (nid1 gt nid2) pairid = concat(sid2, sid1). sort cases by pairid. compute flag = 0. if pairid = lag(pairid) flag = 1. exe.
The final data set is shown below.
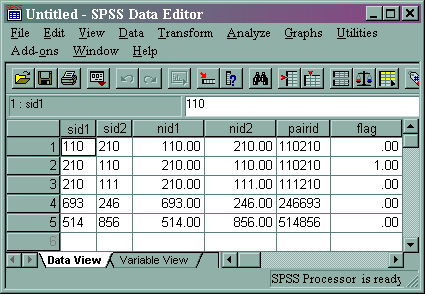
Once you have identified the duplicates, you can easily filter or delete them from your data set.