If you have been working on your data in SPSS, but need to move to Mplus to complete your analysis, you can prep and save your data in a form that Mplus can read. We will be preparing the dataset sample.sav. We can take a quick glance at the first 10 observations in this dataset.
list /cases from 1 to 10.
female race ses schtyp read write
. 3.00 1.00 1.00 34.00 35.00
.00 -9.00 2.00 1.00 44.00 41.00
.00 4.00 -99.00 1.00 55.00 39.00
1.00 2.00 3.00 -999.00 60.00 59.00
.00 4.00 1.00 1.00 -9999.00 37.00
.00 4.00 2.00 1.00 34.00 -99999.00
.00 3.00 2.00 1.00 34.00 37.00
1.00 4.00 1.00 1.00 35.00 35.00
.00 4.00 3.00 1.00 44.00 33.00
1.00 4.00 3.00 2.00 36.00 57.00
Step 0. Summary statistics
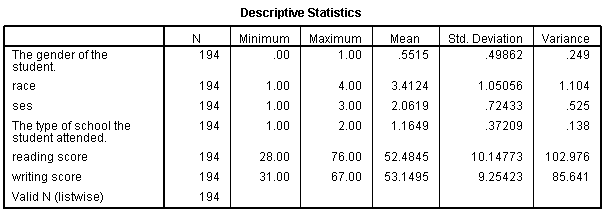
While not a required step, running summary statistics in SPSS before moving to Mplus provides a needed reference point for checking that your data has been read into Mplus correctly. If the summary statistics you see in Mplus do not match these that were calculated before the transfer, you will know to check for errors in the process. In order for these summaries to be consistent with those in Mplus, we will indicate missing = listwise in our syntax.
desc var=all /stat=default variance.
Step 1. Numeric data only
Mplus cannot read in character data, so any character variables in your dataset must be either 1) converted to numeric or 2) omitted. Looking at the variable view of our dataset,
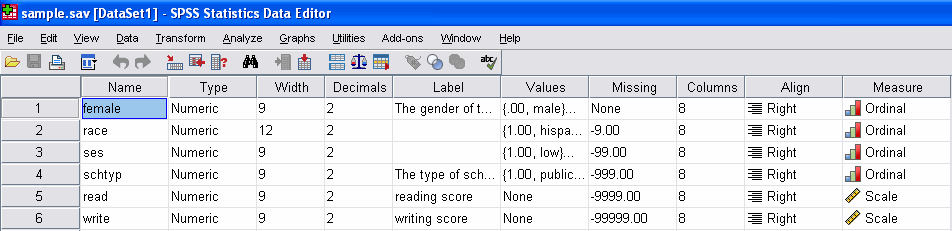
we can see that all of our variables are numeric. For details on recoding variables, see our SPSS Learning Modules.
Step 2. Short variable names
Variable names in Mplus cannot exceed 8 characters. If your variable names exceed this length, they must be shortened. All of our variable names are 8 or fewer characters.
Step 3. Missing values
Before reading your data into Mplus, you must be familiar with whether or not your data contains missing values and, if it does, how they are coded. In Mplus, you will need to explicitly list out the values that represent missing data. In our dataset, we can see that different variables have different values for missing. We can note which variables have which system missing values in SPSS: (.) for female, -9 for race, -99 for ses, -999 for schtyp, -9999 for read, and -99999 for write. Note that although missing values for female are shown with a dot (.) in the SPSS Data Editor, in the .csv file, they will be a blank.
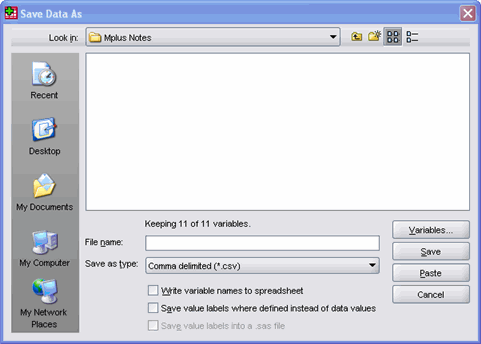
Step 4. Save as .csv
Mplus can easily read comma separated data, so we can save our dataset as a .csv file. This can be done by choosing File, Save as, and then choosing “Comma delimited” from the “Save as type” drop down list. Also, we do not want the .csv file we create to include variable names, so we uncheck the “Write variable names to spreadsheet” box.
We can open the .csv file in Notepad or another text editor to see what our raw data looks like.
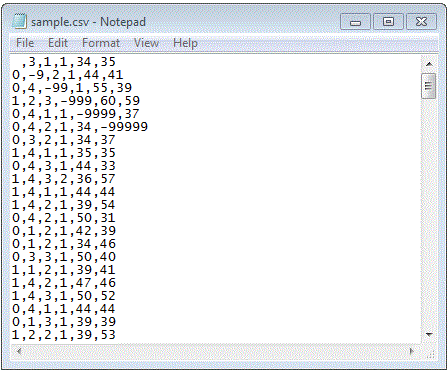
When reading in the data, we will refer Mplus to this file.
Step 5. List of variable names
Instead of providing Mplus with a dataset containing variable names, you instead direct Mplus to a file without names and give the names within the code. To make this easier, we can save the variable names quickly from SPSS by copying them from the Variable View window and pasting them into a new text editor or directly into an Mplus input file.
We are now ready to read our data into Mplus. In the code below, we indicate the location of the .csv file we saved (NOTE: Mplus limits input lines to 80 characters, so a lengthy pathname may cause an error.) and indicate listwise deletion should be used in the analysis, just as we did in SPSS. We paste our list of variables in the Variable: block after Names are. In the next line, we indicate which values should be considered missing in each variable. Lastly, we indicate Type = basic in the Analysis: block so that the output includes summary statistics that allow us to check that the data was read in correctly. Below the code, we have printed some of the output that can be used to 1) make sure our missing values were correctly entered and 2) check the variable means.
Title:
Entering data from .csv file
Data:
File is "D:/data/sample.csv";
Listwise = on;
Variable:
Names are
id female race ses schtyp prog read write;
Missing is
race (-9) ses (-99) schtyp (-999) read (-9999) write (-99999);
Analysis:
Type = basic;
INPUT READING TERMINATED NORMALLY
< ... output omitted ... >
SUMMARY OF MISSING DATA PATTERNS
MISSING DATA PATTERNS (x = not missing)
1 2 3 4 5 6 7
FEMALE x x x x x x
RACE x x x x x x
SES x x x x x x
SCHTYP x x x x x x
READ x x x x x x
WRITE x x x x x x
MISSING DATA PATTERN FREQUENCIES
Pattern Frequency Pattern Frequency Pattern Frequency
1 194 4 1 7 1
2 1 5 1
3 1 6 1
< ... output omitted ... >
SAMPLE STATISTICS
Means
FEMALE RACE SES SCHTYP READ
________ ________ ________ ________ ________
1 0.552 3.412 2.062 1.165 52.485
Means
WRITE
________
1 53.149
We can compare these missing data patterns and means to our summaries from SPSS. In both datasets, we have 194 complete cases and our variable means match.