Page 272
use "A:table74.dta", clear rename col1 a rename col2 x gen index = _n gen b = mod(index, 4) replace b = 4 if b == 0 anova x b
Number of obs = 20 R-squared = 0.2702
Root MSE = 2.66927 Adj R-squared = 0.1333
Source | Partial SS df MS F Prob > F
-----------+----------------------------------------------------
Model | 42.2 3 14.0666667 1.97 0.1585
|
b | 42.2 3 14.0666667 1.97 0.1585
|
Residual | 114 16 7.125
-----------+----------------------------------------------------
Total | 156.2 19 8.22105263
Page 274 Note that b is the row number. In the syntax below, the notation in the square brackets represent the subcript.
sort b a by b: gen c = abs(x-x[a+1]) drop if c == . list b c
+-------+
| b c |
|-------|
1. | 1 3 |
2. | 1 4 |
3. | 1 1 |
4. | 1 2 |
5. | 2 6 |
|-------|
6. | 2 2 |
7. | 2 2 |
8. | 2 1 |
9. | 3 3 |
10. | 3 2 |
|-------|
11. | 3 9 |
12. | 3 7 |
13. | 4 0 |
14. | 4 2 |
15. | 4 5 |
|-------|
16. | 4 6 |
+-------+
Page 275, example 7.7 NOTE: There seems to be a problem with the second to last sample (taking case 74 instead of 75).
infix str22 location 3-21 temp1 23-25 per1 27-30 temp2 32-34 per2 36-38 temp3 40-42 /* */ per3 44-46 temp4 49-50 per4 52-54 temp5 57-58 per5 60-62 using "a:temps.dat" drop if _n == 89 gen id = _n gen sample = 0 replace sample = 1 if _n==20 replace sample = 1 if _n==31 replace sample = 1 if _n==42 replace sample = 1 if _n==53 replace sample = 1 if _n==64 replace sample = 1 if _n==74 replace sample = 1 if _n==86 replace sample = 1 if _n==9 gen x = id/10 scatter per1 x if sample == 1, xlabel(1.6(1.6)8)
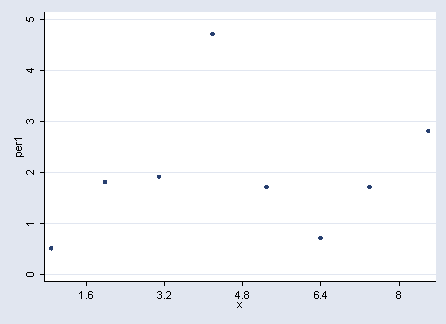
tabstat per1 if sample == 1, s(mean var)
variable | mean variance
-------------+--------------------
per1 | 1.975 1.727857
----------------------------------
Page 277, example 7.8 and Figure 7.5 NOTE: You will need to create a data dictionary in order to read the raw data file into Stata. You can download the dictionary by clicking here. Notice that the infile command calls the /stata/examples/ess5/river.dct file, which is the dictionary file, not the raw data file. Within the dictionary file, the raw data file is called. You can view the dictionary file in a text editor, such as NotePad, or you can view it in the Do File editor. To see the dictionary files, change the Files of Type default in the Open File window. You can see the data printed out in the text on pages 491-492.
set more off
infile using "A:/stata/examples/ess5/river.dct"
drop if _n == 32
compress
reshape long water, i(day) j(time)
gen sample = 0
* NOTE: day corresponds to the day listed on page 491 of the text,
* and time refers to the month. Hence, time==1 because Oct 1977 is the first month listed.
replace sample = 1 if day==4 & time==1
replace sample = 1 if day==14 & time==1
replace sample = 1 if day==24 & time==1
replace sample = 1 if day==3 & time==2
replace sample = 1 if day==13 & time==2
replace sample = 1 if day==23 & time==2
replace sample = 1 if day==3 & time==3
replace sample = 1 if day==13 & time==3
replace sample = 1 if day==23 & time==3
list if sample == 1
sort sample time day
by sample: gen x = _n
sort time day
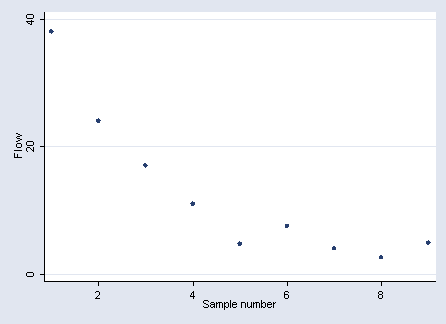
scatter water x if sample == 1, xlabel(2(2)8) ylabel(0 20 40) xtitle("Sample number") ytitle("Flow")