Chapter Outline
- 1.0 Introduction
- 1.1 A First Regression Analysis
- 1.2 Examining Data
- 1.3 Simple linear regression
- 1.4 Multiple regression
- 1.5 Transforming variables
- 1.6 Summary
- 1.7 Self assessment
- 1.8 For more information
1.0 Introduction
This book is composed of four chapters covering a variety of topics about using Stata for regression. We should emphasize that this book is about “data analysis” and that it demonstrates how Stata can be used for regression analysis, as opposed to a book that covers the statistical basis of multiple regression. We assume that you have had at least one statistics course covering regression analysis and that you have a regression book that you can use as a reference (see the Regression With Stata page and our Statistics Books for Loan page for recommended regression analysis books). This book is designed to apply your knowledge of regression, combine it with instruction on Stata, to perform, understand and interpret regression analyses.
This first chapter will cover topics in simple and multiple regression, as well as the supporting tasks that are important in preparing to analyze your data, e.g., data checking, getting familiar with your data file, and examining the distribution of your variables. We will illustrate the basics of simple and multiple regression and demonstrate the importance of inspecting, checking and verifying your data before accepting the results of your analysis. In general, we hope to show that the results of your regression analysis can be misleading without further probing of your data, which could reveal relationships that a casual analysis could overlook.
In this chapter, and in subsequent chapters, we will be using a data file that was created by randomly sampling 400 elementary schools from the California Department of Education’s API 2000 dataset. This data file contains a measure of school academic performance as well as other attributes of the elementary schools, such as, class size, enrollment, poverty, etc.
You can access this data file over the web from within Stata with the Stata use command as shown below. Note: Do not type the leading dot in the command — the dot is a convention to indicate that the statement is a Stata command.
use https://stats.idre.ucla.edu/stat/stata/webbooks/reg/elemapi
Once you have read the file, you probably want to store a copy of it on your computer (so you don’t need to read it over the web every time). Let’s say you are using Windows and want to store the file in a folder called c:regstata (you can choose a different name if you like). First, you can make this folder within Stata using the mkdir command.
mkdir c:regstata
We can then change to that directory using the cd command.
cd c:regstata
And then if you save the file it will be saved in the c:regstata folder. Let’s save the file as elemapi .
save elemapi
Now the data file is saved as c:regstataelemapi.dta and you could quit Stata and the data file would still be there. When you wish to use the file in the future, you would just use the cd command to change to the c:regstata directory (or whatever you called it) and then use the elemapi file.
cd c:regstata use elemapi
1.1 A First Regression Analysis
Let’s dive right in and perform a regression analysis using the variables api00, acs_k3, meals and full. These measure the academic performance of the school (api00), the average class size in kindergarten through 3rd grade (acs_k3), the percentage of students receiving free meals (meals) – which is an indicator of poverty, and the percentage of teachers who have full teaching credentials (full). We expect that better academic performance would be associated with lower class size, fewer students receiving free meals, and a higher percentage of teachers having full teaching credentials. Below, we show the Stata command for testing this regression model followed by the Stata output.
regress api00 acs_k3 meals full
Source | SS df MS Number of obs = 313
-------------+------------------------------ F( 3, 309) = 213.41
Model | 2634884.26 3 878294.754 Prob > F = 0.0000
Residual | 1271713.21 309 4115.57673 R-squared = 0.6745
-------------+------------------------------ Adj R-squared = 0.6713
Total | 3906597.47 312 12521.1457 Root MSE = 64.153
------------------------------------------------------------------------------
api00 | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
acs_k3 | -2.681508 1.393991 -1.92 0.055 -5.424424 .0614073
meals | -3.702419 .1540256 -24.04 0.000 -4.005491 -3.399348
full | .1086104 .090719 1.20 0.232 -.0698947 .2871154
_cons | 906.7392 28.26505 32.08 0.000 851.1228 962.3555
------------------------------------------------------------------------------
Let’s focus on the three predictors, whether they are statistically significant and, if so, the direction of the relationship. The average class size (acs_k3, b=-2.68), is not statistically significant at the 0.05 level (p=0.055), but only just so. The coefficient is negative which would indicate that larger class size is related to lower academic performance — which is what we would expect. Next, the effect of meals (b=-3.70, p=.000) is significant and its coefficient is negative indicating that the greater the proportion students receiving free meals, the lower the academic performance. Please note, that we are not saying that free meals are causing lower academic performance. The meals variable is highly related to income level and functions more as a proxy for poverty. Thus, higher levels of poverty are associated with lower academic performance. This result also makes sense. Finally, the percentage of teachers with full credentials (full, b=0.11, p=.232) seems to be unrelated to academic performance. This would seem to indicate that the percentage of teachers with full credentials is not an important factor in predicting academic performance — this result was somewhat unexpected.
Should we take these results and write them up for publication? From these results, we would conclude that lower class sizes are related to higher performance, that fewer students receiving free meals is associated with higher performance, and that the percentage of teachers with full credentials was not related to academic performance in the schools. Before we write this up for publication, we should do a number of checks to make sure we can firmly stand behind these results. We start by getting more familiar with the data file, doing preliminary data checking, looking for errors in the data.
1.2 Examining data
First, let’s use the describe command to learn more about this data file. We can verify how many observations it has and see the names of the variables it contains. To do this, we simply type
describe
Contains data from https://stats.idre.ucla.edu/stat/stata/webbooks/reg/elemapi.dta
obs: 400
vars: 21 25 Feb 2001 16:58
size: 14,800 (92.3% of memory free)
-------------------------------------------------------------------------------
storage display value
variable name type format label variable label
-------------------------------------------------------------------------------
snum int %9.0g school number
dnum int %7.0g dname district number
api00 int %6.0g api 2000
api99 int %6.0g api 1999
growth int %6.0g growth 1999 to 2000
meals byte %4.0f pct free meals
ell byte %4.0f english language learners
yr_rnd byte %4.0f yr_rnd year round school
mobility byte %4.0f pct 1st year in school
acs_k3 byte %4.0f avg class size k-3
acs_46 byte %4.0f avg class size 4-6
not_hsg byte %4.0f parent not hsg
hsg byte %4.0f parent hsg
some_col byte %4.0f parent some college
col_grad byte %4.0f parent college grad
grad_sch byte %4.0f parent grad school
avg_ed float %9.0g avg parent ed
full float %4.0f pct full credential
emer byte %4.0f pct emer credential
enroll int %9.0g number of students
mealcat byte %18.0g mealcat Percentage free meals in 3
categories
-------------------------------------------------------------------------------
Sorted by: dnum
We will not go into all of the details of this output. Note that there are 400 observations and 21 variables. We have variables about academic performance in 2000 and 1999 and the change in performance, api00, api99 and growth respectively. We also have various characteristics of the schools, e.g., class size, parents education, percent of teachers with full and emergency credentials, and number of students. Note that when we did our original regression analysis it said that there were 313 observations, but the describe command indicates that we have 400 observations in the data file.
If you want to learn more about the data file, you could list all or some of the observations. For example, below we list the first five observations.
list in 1/5
Observation 1
snum 906 dnum 41 api00 693
api99 600 growth 93 meals 67
ell 9 yr_rnd No mobility 11
acs_k3 16 acs_46 22 not_hsg 0
hsg 0 some_col 0 col_grad 0
grad_sch 0 avg_ed . full 76.00
emer 24 enroll 247 mealcat 47-80% free
Observation 2
snum 889 dnum 41 api00 570
api99 501 growth 69 meals 92
ell 21 yr_rnd No mobility 33
acs_k3 15 acs_46 32 not_hsg 0
hsg 0 some_col 0 col_grad 0
grad_sch 0 avg_ed . full 79.00
emer 19 enroll 463 mealcat 81-100% free
Observation 3
snum 887 dnum 41 api00 546
api99 472 growth 74 meals 97
ell 29 yr_rnd No mobility 36
acs_k3 17 acs_46 25 not_hsg 0
hsg 0 some_col 0 col_grad 0
grad_sch 0 avg_ed . full 68.00
emer 29 enroll 395 mealcat 81-100% free
Observation 4
snum 876 dnum 41 api00 571
api99 487 growth 84 meals 90
ell 27 yr_rnd No mobility 27
acs_k3 20 acs_46 30 not_hsg 36
hsg 45 some_col 9 col_grad 9
grad_sch 0 avg_ed 1.91 full 87.00
emer 11 enroll 418 mealcat 81-100% free
Observation 5
snum 888 dnum 41 api00 478
api99 425 growth 53 meals 89
ell 30 yr_rnd No mobility 44
acs_k3 18 acs_46 31 not_hsg 50
hsg 50 some_col 0 col_grad 0
grad_sch 0 avg_ed 1.5 full 87.00
emer 13 enroll 520 mealcat 81-100% free
This takes up lots of space on the page, but does not give us a lot of information. Listing our data can be very helpful, but it is more helpful if you list just the variables you are interested in. Let’s list the first 10 observations for the variables that we looked at in our first regression analysis.
list api00 acs_k3 meals full in 1/10
api00 acs~3 meals full
1. 693 16 67 76.00
2. 570 15 92 79.00
3. 546 17 97 68.00
4. 571 20 90 87.00
5. 478 18 89 87.00
6. 858 20 . 100.00
7. 918 19 . 100.00
8. 831 20 . 96.00
9. 860 20 . 100.00
10. 737 21 29 96.00
We see that among the first 10 observations, we have four missing values for meals. It is likely that the missing data for meals had something to do with the fact that the number of observations in our first regression analysis was 313 and not 400.
Another useful tool for learning about your variables is the codebook command. Let’s do codebook for the variables we included in the regression analysis, as well as the variable yr_rnd. We have interspersed some comments on this output in [square brackets and in bold].
codebook api00 acs_k3 meals full yr_rnd
api00 ---------------------------------------------------------------- api 2000
type: numeric (int)
range: [369,940] units: 1
unique values: 271 coded missing: 0 / 400
mean: 647.622
std. dev: 142.249
percentiles: 10% 25% 50% 75% 90%
465.5 523.5 643 762.5 850
[the api scores don't have any missing values, and range from 369-940]
[this makes sense since the api scores can range from 200 to 1000]
acs_k3 ----------------------------------------------------- avg class size k-3
type: numeric (byte)
range: [-21,25] units: 1
unique values: 14 coded missing: 2 / 400
mean: 18.5477
std. dev: 5.00493
percentiles: 10% 25% 50% 75% 90%
17 18 19 20 21
[the average class size ranges from -21 to 25 and 2 are missing.]
[it seems odd for a class size to be -21]
meals ---------------------------------------------------------- pct free meals
type: numeric (byte)
range: [6,100] units: 1
unique values: 80 coded missing: 85 / 400
mean: 71.9937
std. dev: 24.3856
percentiles: 10% 25% 50% 75% 90%
33 57 77 93 99
[the percent receiving free meals ranges from 6 to 100, but 85 are missing]
[this seems like a large number of missing values!]
full ------------------------------------------------------ pct full credential
type: numeric (float)
range: [.42,100] units: .01
unique values: 92 coded missing: 0 / 400
mean: 66.0568
std. dev: 40.2979
percentiles: 10% 25% 50% 75% 90%
67 .95 87 97 100
[The percent credentialed ranges from .42 to 100 with no missing]
yr_rnd ------------------------------------------------------ year round school
type: numeric (byte)
label: yr_rnd
range: [0,1] units: 1
unique values: 2 coded missing: 0 / 400
tabulation: Freq. Numeric Label
308 0 No
92 1 Yes
[the variable yr_rnd is coded 0=No (not year round) and 1=Yes (year round)]
[308 are non-year round and 92 are year round, and none are missing]
The codebook command has uncovered a number of peculiarities worthy of further examination. Let’s use the summarize command to learn more about these variables. As shown below, the summarize command also reveals the large number of missing values for meals (400 – 315 = 85) and we see the unusual minimum for acs_k3 of -21.
summarize api00 acs_k3 meals full
Variable | Obs Mean Std. Dev. Min Max
-------------+-----------------------------------------------------
api00 | 400 647.6225 142.249 369 940
acs_k3 | 398 18.54774 5.004933 -21 25
meals | 315 71.99365 24.38557 6 100
full | 400 66.0568 40.29793 .42 100
Let’s get a more detailed summary for acs_k3. In Stata, the comma after the variable list indicates that options follow, in this case, the option is detail. As you can see below, the detail option gives you the percentiles, the four largest and smallest values, measures of central tendency and variance, etc. Note that summarize, and other commands, can be abbreviated: we could have typed sum acs_k3, d.
summarize acs_k3, detail
avg class size k-3
-------------------------------------------------------------
Percentiles Smallest
1% -20 -21
5% 16 -21
10% 17 -21 Obs 398
25% 18 -20 Sum of Wgt. 398
50% 19 Mean 18.54774
Largest Std. Dev. 5.004933
75% 20 23
90% 21 23 Variance 25.04935
95% 21 23 Skewness -7.078785
99% 23 25 Kurtosis 55.33497
It seems as though some of the class sizes somehow became negative, as though a negative sign was incorrectly typed in front of them. Let’s do a tabulate of class size to see if this seems plausible.
tabulate acs_k3
avg class |
size k-3 | Freq. Percent Cum.
------------+-----------------------------------
-21 | 3 0.75 0.75
-20 | 2 0.50 1.26
-19 | 1 0.25 1.51
14 | 2 0.50 2.01
15 | 1 0.25 2.26
16 | 14 3.52 5.78
17 | 20 5.03 10.80
18 | 64 16.08 26.88
19 | 143 35.93 62.81
20 | 97 24.37 87.19
21 | 40 10.05 97.24
22 | 7 1.76 98.99
23 | 3 0.75 99.75
25 | 1 0.25 100.00
------------+-----------------------------------
Total | 398 100.00
Indeed, it seems that some of the class sizes somehow got negative signs put in front of them. Let’s look at the school and district number for these observations to see if they come from the same district. Indeed, they all come from district 140.
list snum dnum acs_k3 if acs_k3 < 0
snum dnum acs~3
37. 602 140 -21
96. 600 140 -20
173. 595 140 -21
223. 596 140 -19
229. 611 140 -20
282. 592 140 -21
Let’s look at all of the observations for district 140.
list dnum snum api00 acs_k3 meals full if dnum == 140
dnum snum api00 acs~3 meals full
37. 140 602 864 -21 . 100.00
96. 140 600 843 -20 . 91.00
173. 140 595 713 -21 63 92.00
223. 140 596 800 -19 . 94.00
229. 140 611 857 -20 . 100.00
282. 140 592 804 -21 . 97.00
All of the observations from district 140 seem to have this problem. When you find such a problem, you want to go back to the original source of the data to verify the values. We have to reveal that we fabricated this error for illustration purposes, and that the actual data had no such problem. Let’s pretend that we checked with district 140 and there was a problem with the data there, a hyphen was accidentally put in front of the class sizes making them negative. We will make a note to fix this! Let’s continue checking our data.
Let’s take a look at some graphical methods for inspecting data. For each variable, it is useful to inspect them using a histogram, boxplot, and stem-and-leaf plot. These graphs can show you information about the shape of your variables better than simple numeric statistics can. We already know about the problem with acs_k3, but let’s see how these graphical methods would have revealed the problem with this variable.
First, we show a histogram for acs_k3. This shows us the observations where the average class size is negative.
histogram acs_k3
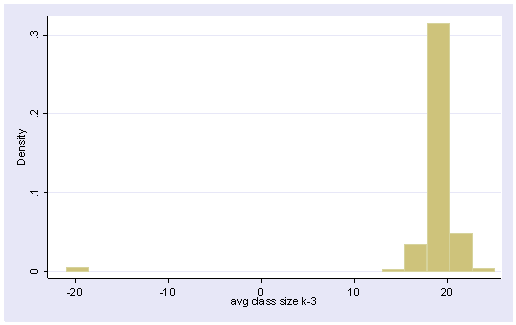
Likewise, a boxplot would have called these observations to our attention as well. You can see the outlying negative observations way at the bottom of the boxplot.
graph box acs_k3
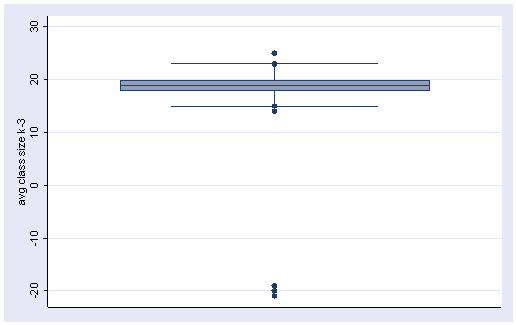
Finally, a stem-and-leaf plot would also have helped to identify these observations. This plot shows the exact values of the observations, indicating that there were three -21s, two -20s, and one -19.
stem acs_k3 Stem-and-leaf plot for acs_k3 (avg class size k-3) -2* | 11100 -1. | 9 -1s | -1f | -1t | -1* | -0. | -0s | -0f | -0t | -0* | 0* | 0t | 0f | 0s | 0. | 1* | 1t | 1f | 445 1s | 6666666666666677777777777777777777 1. | 88888888888888888888888888888888888888888888888888888888888888 ... (207) 2* | 00000000000000000000000000000000000000000000000000000000000000 ... (137) 2t | 2222222333 2f | 5
We recommend plotting all of these graphs for the variables you will be analyzing. We will omit, due to space considerations, showing these graphs for all of the variables. However, in examining the variables, the stem-and-leaf plot for full seemed rather unusual. Up to now, we have not seen anything problematic with this variable, but look at the stem and leaf plot for full below. It shows 104 observations where the percent with a full credential is less than one. This is over 25% of the schools, and seems very unusual.
stem full Stem-and-leaf plot for full (pct full credential) full rounded to nearest multiple of .1 plot in units of .1 0** | 04,04,05,05,05,05,05,05,05,05,05,05,06,06,06,06,06,06,06,06, ... (104) 0** | 0** | 0** | 0** | 1** | 1** | 1** | 1** | 1** | 2** | 2** | 2** | 2** | 2** | 3** | 3** | 3** | 3** | 70 3** | 4** | 10 4** | 4** | 40,40,50,50 4** | 60 4** | 80 5** | 5** | 30 5** | 5** | 70 5** | 80,80,80,90 6** | 10 6** | 30,30 6** | 40,50 6** | 6** | 80,80,90,90,90 7** | 00,10,10,10 7** | 20,30,30 7** | 40,50,50,50,50 7** | 60,60,60,60,70,70 7** | 80,80,80,80,90,90,90 8** | 00,00,00,00,00,00,00,00,00,00,10,10,10,10 8** | 20,20,20,30,30,30,30,30,30,30,30,30 8** | 40,40,40,40,50,50,50,50,50,50,50,50 8** | 60,60,60,60,60,70,70,70,70,70,70,70,70,70,70,70,70 8** | 80,80,80,80,80,80,90,90,90,90,90 9** | 00,00,00,00,00,00,00,00,00,10,10,10,10,10,10,10,10 9** | 20,20,20,20,20,20,20,30,30,30,30,30,30,30,30,30,30,30,30 9** | 40,40,40,40,40,40,40,40,40,40,50,50,50,50,50,50,50,50,50,50, ... (27) 9** | 60,60,60,60,60,60,60,60,60,60,60,60,60,60,60,60,60,70,70,70, ... (28) 9** | 80,80,80,80,80,80,80,80,80 10** | 00,00,00,00,00,00,00,00,00,00,00,00,00,00,00,00,00,00,00,00, ... (81)
Let’s look at the frequency distribution of full to see if we can understand this better. The values go from 0.42 to 1.0, then jump to 37 and go up from there. It appears as though some of the percentages are actually entered as proportions, e.g., 0.42 was entered instead of 42 or 0.96 which really should have been 96.
tabulate full
pct full |
credential | Freq. Percent Cum.
------------+-----------------------------------
0.42 | 1 0.25 0.25
0.45 | 1 0.25 0.50
0.46 | 1 0.25 0.75
0.47 | 1 0.25 1.00
0.48 | 1 0.25 1.25
0.50 | 3 0.75 2.00
0.51 | 1 0.25 2.25
0.52 | 1 0.25 2.50
0.53 | 1 0.25 2.75
0.54 | 1 0.25 3.00
0.56 | 2 0.50 3.50
0.57 | 2 0.50 4.00
0.58 | 1 0.25 4.25
0.59 | 3 0.75 5.00
0.60 | 1 0.25 5.25
0.61 | 4 1.00 6.25
0.62 | 2 0.50 6.75
0.63 | 1 0.25 7.00
0.64 | 3 0.75 7.75
0.65 | 3 0.75 8.50
0.66 | 2 0.50 9.00
0.67 | 6 1.50 10.50
0.68 | 2 0.50 11.00
0.69 | 3 0.75 11.75
0.70 | 1 0.25 12.00
0.71 | 1 0.25 12.25
0.72 | 2 0.50 12.75
0.73 | 6 1.50 14.25
0.75 | 4 1.00 15.25
0.76 | 2 0.50 15.75
0.77 | 2 0.50 16.25
0.79 | 3 0.75 17.00
0.80 | 5 1.25 18.25
0.81 | 8 2.00 20.25
0.82 | 2 0.50 20.75
0.83 | 2 0.50 21.25
0.84 | 2 0.50 21.75
0.85 | 3 0.75 22.50
0.86 | 2 0.50 23.00
0.90 | 3 0.75 23.75
0.92 | 1 0.25 24.00
0.93 | 1 0.25 24.25
0.94 | 2 0.50 24.75
0.95 | 2 0.50 25.25
0.96 | 1 0.25 25.50
1.00 | 2 0.50 26.00
37.00 | 1 0.25 26.25
41.00 | 1 0.25 26.50
44.00 | 2 0.50 27.00
45.00 | 2 0.50 27.50
46.00 | 1 0.25 27.75
48.00 | 1 0.25 28.00
53.00 | 1 0.25 28.25
57.00 | 1 0.25 28.50
58.00 | 3 0.75 29.25
59.00 | 1 0.25 29.50
61.00 | 1 0.25 29.75
63.00 | 2 0.50 30.25
64.00 | 1 0.25 30.50
65.00 | 1 0.25 30.75
68.00 | 2 0.50 31.25
69.00 | 3 0.75 32.00
70.00 | 1 0.25 32.25
71.00 | 3 0.75 33.00
72.00 | 1 0.25 33.25
73.00 | 2 0.50 33.75
74.00 | 1 0.25 34.00
75.00 | 4 1.00 35.00
76.00 | 4 1.00 36.00
77.00 | 2 0.50 36.50
78.00 | 4 1.00 37.50
79.00 | 3 0.75 38.25
80.00 | 10 2.50 40.75
81.00 | 4 1.00 41.75
82.00 | 3 0.75 42.50
83.00 | 9 2.25 44.75
84.00 | 4 1.00 45.75
85.00 | 8 2.00 47.75
86.00 | 5 1.25 49.00
87.00 | 12 3.00 52.00
88.00 | 6 1.50 53.50
89.00 | 5 1.25 54.75
90.00 | 9 2.25 57.00
91.00 | 8 2.00 59.00
92.00 | 7 1.75 60.75
93.00 | 12 3.00 63.75
94.00 | 10 2.50 66.25
95.00 | 17 4.25 70.50
96.00 | 17 4.25 74.75
97.00 | 11 2.75 77.50
98.00 | 9 2.25 79.75
100.00 | 81 20.25 100.00
------------+-----------------------------------
Total | 400 100.00
Let’s see which district(s) these data came from.
tabulate dnum if full <= 1
district |
number | Freq. Percent Cum.
------------+-----------------------------------
401 | 104 100.00 100.00
------------+-----------------------------------
Total | 104 100.00
We note that all 104 observations in which full was less than or equal to one came from district 401. Let’s count how many observations there are in district 401 using the count command and we see district 401 has 104 observations.
count if dnum==401 104
All of the observations from this district seem to be recorded as proportions instead of percentages. Again, let us state that this is a pretend problem that we inserted into the data for illustration purposes. If this were a real life problem, we would check with the source of the data and verify the problem. We will make a note to fix this problem in the data as well.
Another useful graphical technique for screening your data is a scatterplot matrix. While this is probably more relevant as a diagnostic tool searching for non-linearities and outliers in your data, it can also be a useful data screening tool, possibly revealing information in the joint distributions of your variables that would not be apparent from examining univariate distributions. Let’s look at the scatterplot matrix for the variables in our regression model. This reveals the problems we have already identified, i.e., the negative class sizes and the percent full credential being entered as proportions.
graph matrix api00 acs_k3 meals full, half
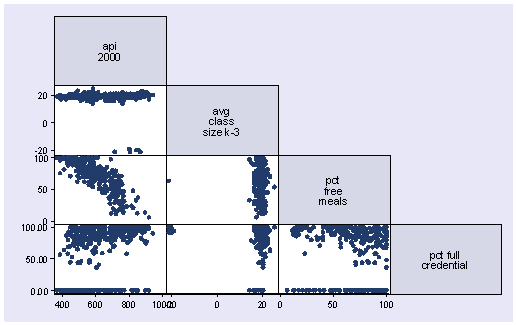
We have identified three problems in our data. There are numerous missing values for meals, there were negatives accidentally inserted before some of the class sizes (acs_k3) and over a quarter of the values for full were proportions instead of percentages. The corrected version of the data is called elemapi2. Let’s use that data file and repeat our analysis and see if the results are the same as our original analysis. First, let’s repeat our original regression analysis below.
regress api00 acs_k3 meals full
Source | SS df MS Number of obs = 313
-------------+------------------------------ F( 3, 309) = 213.41
Model | 2634884.26 3 878294.754 Prob > F = 0.0000
Residual | 1271713.21 309 4115.57673 R-squared = 0.6745
-------------+------------------------------ Adj R-squared = 0.6713
Total | 3906597.47 312 12521.1457 Root MSE = 64.153
------------------------------------------------------------------------------
api00 | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
acs_k3 | -2.681508 1.393991 -1.92 0.055 -5.424424 .0614073
meals | -3.702419 .1540256 -24.04 0.000 -4.005491 -3.399348
full | .1086104 .090719 1.20 0.232 -.0698947 .2871154
_cons | 906.7392 28.26505 32.08 0.000 851.1228 962.3555
------------------------------------------------------------------------------
Now, let’s use the corrected data file and repeat the regression analysis. We see quite a difference in the results! In the original analysis (above), acs_k3 was nearly significant, but in the corrected analysis (below) the results show this variable to be not significant, perhaps due to the cases where class size was given a negative value. Likewise, the percentage of teachers with full credentials was not significant in the original analysis, but is significant in the corrected analysis, perhaps due to the cases where the value was given as the proportion with full credentials instead of the percent. Also, note that the corrected analysis is based on 398 observations instead of 313 observations, due to getting the complete data for the meals variable which had lots of missing values.
use https://stats.idre.ucla.edu/stat/stata/webbooks/reg/elemapi2
regress api00 acs_k3 meals full
Source | SS df MS Number of obs = 398
-------------+------------------------------ F( 3, 394) = 615.55
Model | 6604966.18 3 2201655.39 Prob > F = 0.0000
Residual | 1409240.96 394 3576.7537 R-squared = 0.8242
-------------+------------------------------ Adj R-squared = 0.8228
Total | 8014207.14 397 20186.9197 Root MSE = 59.806
------------------------------------------------------------------------------
api00 | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
acs_k3 | -.7170622 2.238821 -0.32 0.749 -5.118592 3.684468
meals | -3.686265 .1117799 -32.98 0.000 -3.906024 -3.466505
full | 1.327138 .2388739 5.56 0.000 .857511 1.796765
_cons | 771.6581 48.86071 15.79 0.000 675.5978 867.7184
------------------------------------------------------------------------------
From this point forward, we will use the corrected, elemapi2, data file. You might want to save this on your computer so you can use it in future analyses.
save elemapi2
So far we have covered some topics in data checking/verification, but we have not really discussed regression analysis itself. Let’s now talk more about performing regression analysis in Stata.
1.3 Simple Linear Regression
Let’s begin by showing some examples of simple linear regression using Stata. In this type of regression, we have only one predictor variable. This variable may be continuous, meaning that it may assume all values within a range, for example, age or height, or it may be dichotomous, meaning that the variable may assume only one of two values, for example, 0 or 1. The use of categorical variables with more than two levels will be covered in Chapter 3. There is only one response or dependent variable, and it is continuous.
In Stata, the dependent variable is listed immediately after the regress command followed by one or more predictor variables. Let’s examine the relationship between the size of school and academic performance to see if the size of the school is related to academic performance. For this example, api00 is the dependent variable and enroll is the predictor.
regress api00 enroll
Source | SS df MS Number of obs = 400
-------------+------------------------------ F( 1, 398) = 44.83
Model | 817326.293 1 817326.293 Prob > F = 0.0000
Residual | 7256345.70 398 18232.0244 R-squared = 0.1012
-------------+------------------------------ Adj R-squared = 0.0990
Total | 8073672.00 399 20234.7669 Root MSE = 135.03
------------------------------------------------------------------------------
api00 | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
enroll | -.1998674 .0298512 -6.70 0.000 -.2585532 -.1411817
_cons | 744.2514 15.93308 46.71 0.000 712.9279 775.5749
------------------------------------------------------------------------------
Let’s review this output a bit more carefully. First, we see that the F-test is statistically significant, which means that the model is statistically significant. The R-squared of .1012 means that approximately 10% of the variance of api00 is accounted for by the model, in this case, enroll. The t-test for enroll equals -6.70, and is statistically significant, meaning that the regression coefficient for enroll is significantly different from zero. Note that (-6.70)2 = 44.89, which is the same as the F-statistic (with some rounding error). The coefficient for enroll is -.1998674, or approximately -.2, meaning that for a one unit increase in enroll, we would expect a .2-unit decrease in api00. In other words, a school with 1100 students would be expected to have an api score 20 units lower than a school with 1000 students. The constant is 744.2514, and this is the predicted value when enroll equals zero. In most cases, the constant is not very interesting. We have prepared an annotated output which shows the output from this regression along with an explanation of each of the items in it.
In addition to getting the regression table, it can be useful to see a scatterplot of the predicted and outcome variables with the regression line plotted. After you run a regression, you can create a variable that contains the predicted values using the predict command. You can get these values at any point after you run a regress command, but remember that once you run a new regression, the predicted values will be based on the most recent regression. To create predicted values you just type predict and the name of a new variable Stata will give you the fitted values. For this example, our new variable name will be fv, so we will type
predict fv (option xb assumed; fitted values)
If we use the list command, we see that a fitted value has been generated for each observation.
list api00 fv in 1/10
api00 fv 1. 369 542.5851 2. 386 671.4996 3. 386 661.7062 4. 387 541.7857 5. 387 592.1523 6. 394 618.5348 7. 397 543.5845 8. 406 604.5441 9. 411 645.5169 10. 412 491.619
Below we can show a scatterplot of the outcome variable, api00 and the predictor, enroll.
scatter api00 enroll
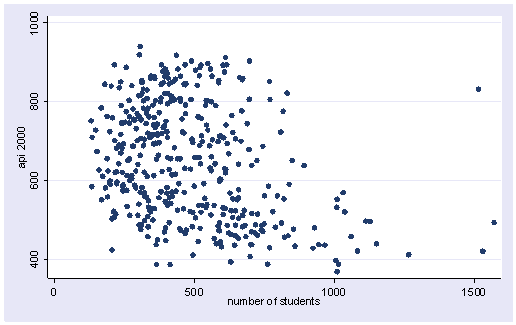
We can combine scatter with lfit to show a scatterplot with fitted values.
twoway (scatter api00 enroll) (lfit api00 enroll)
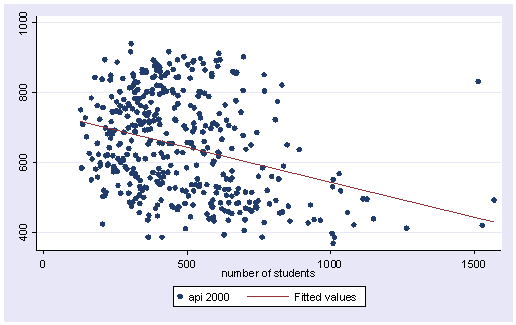
As you see, some of the points appear to be outliers. If you use the mlabel(snum) option on the scatter command, you can see the school number for each point. This allows us to see, for example, that one of the outliers is school 2910.
twoway (scatter api00 enroll, mlabel(snum)) (lfit api00 enroll)
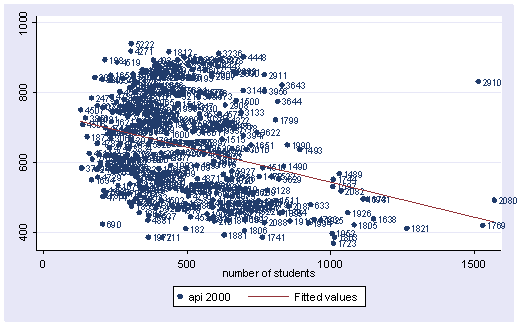
As we saw earlier, the predict command can be used to generate predicted (fitted) values after running regress. You can also obtain residuals by using the predict command followed by a variable name, in this case e, with the residual option.
predict e, residual
This command can be shortened to predict e, resid or even predict e, r. The table below shows some of the other values can that be created with the predict option.
Value to be created Option after Predict --------------------------------------------------- -------------------- predicted values of y (y is the dependent variable) no option needed residuals resid standardized residuals rstandard studentized or jackknifed residuals rstudent leverage lev or hat standard error of the residual stdr Cook's D cooksd standard error of predicted individual y stdf standard error of predicted mean y stdp
1.4 Multiple Regression
Now, let’s look at an example of multiple regression, in which we have one outcome (dependent) variable and multiple predictors. Before we begin with our next example, we need to make a decision regarding the variables that we have created, because we will be creating similar variables with our multiple regression, and we don’t want to get the variables confused. For example, in the simple regression we created a variable fv for our predicted (fitted) values and e for the residuals. If we want to create predicted values for our next example we could call the predicted value something else, e.g., fv_mr, but this could start getting confusing. We could drop the variables we have created, using drop fv e. Instead, let’s clear out the data in memory and use the elemapi2 data file again. When we start new examples in future chapters, we will clear out the existing data file and use the file again to start fresh.
clear use https://stats.idre.ucla.edu/stat/stata/webbooks/reg/elemapi2
For this multiple regression example, we will regress the dependent variable, api00, on all of the predictor variables in the data set.
regress api00 ell meals yr_rnd mobility acs_k3 acs_46 full emer enroll
Source | SS df MS Number of obs = 395
-------------+------------------------------ F( 9, 385) = 232.41
Model | 6740702.01 9 748966.89 Prob > F = 0.0000
Residual | 1240707.78 385 3222.61761 R-squared = 0.8446
-------------+------------------------------ Adj R-squared = 0.8409
Total | 7981409.79 394 20257.3852 Root MSE = 56.768
------------------------------------------------------------------------------
api00 | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
ell | -.8600707 .2106317 -4.08 0.000 -1.274203 -.4459382
meals | -2.948216 .1703452 -17.31 0.000 -3.28314 -2.613293
yr_rnd | -19.88875 9.258442 -2.15 0.032 -38.09218 -1.68531
mobility | -1.301352 .4362053 -2.98 0.003 -2.158995 -.4437089
acs_k3 | 1.3187 2.252683 0.59 0.559 -3.1104 5.747801
acs_46 | 2.032456 .7983213 2.55 0.011 .462841 3.602071
full | .609715 .4758205 1.28 0.201 -.3258169 1.545247
emer | -.7066192 .6054086 -1.17 0.244 -1.89694 .4837018
enroll | -.012164 .0167921 -0.72 0.469 -.0451798 .0208517
_cons | 778.8305 61.68663 12.63 0.000 657.5457 900.1154
------------------------------------------------------------------------------
Let’s examine the output from this regression analysis. As with the simple regression, we look to the p-value of the F-test to see if the overall model is significant. With a p-value of zero to four decimal places, the model is statistically significant. The R-squared is 0.8446, meaning that approximately 84% of the variability of api00 is accounted for by the variables in the model. In this case, the adjusted R-squared indicates that about 84% of the variability of api00 is accounted for by the model, even after taking into account the number of predictor variables in the model. The coefficients for each of the variables indicates the amount of change one could expect in api00 given a one-unit change in the value of that variable, given that all other variables in the model are held constant. For example, consider the variable ell. We would expect a decrease of 0.86 in the api00 score for every one unit increase in ell, assuming that all other variables in the model are held constant. The interpretation of much of the output from the multiple regression is the same as it was for the simple regression. We have prepared an annotated output that more thoroughly explains the output of this multiple regression analysis.
You may be wondering what a 0.86 change in ell really means, and how you might compare the strength of that coefficient to the coefficient for another variable, say meals. To address this problem, we can add an option to the regress command called beta, which will give us the standardized regression coefficients. The beta coefficients are used by some researchers to compare the relative strength of the various predictors within the model. Because the beta coefficients are all measured in standard deviations, instead of the units of the variables, they can be compared to one another. In other words, the beta coefficients are the coefficients that you would obtain if the outcome and predictor variables were all transformed standard scores, also called z-scores, before running the regression.
regress api00 ell meals yr_rnd mobility acs_k3 acs_46 full emer enroll, beta
Source | SS df MS Number of obs = 395
-------------+------------------------------ F( 9, 385) = 232.41
Model | 6740702.01 9 748966.89 Prob > F = 0.0000
Residual | 1240707.78 385 3222.61761 R-squared = 0.8446
-------------+------------------------------ Adj R-squared = 0.8409
Total | 7981409.79 394 20257.3852 Root MSE = 56.768
------------------------------------------------------------------------------
api00 | Coef. Std. Err. t P>|t| Beta
-------------+----------------------------------------------------------------
ell | -.8600707 .2106317 -4.08 0.000 -.1495771
meals | -2.948216 .1703452 -17.31 0.000 -.6607003
yr_rnd | -19.88875 9.258442 -2.15 0.032 -.0591404
mobility | -1.301352 .4362053 -2.98 0.003 -.0686382
acs_k3 | 1.3187 2.252683 0.59 0.559 .0127287
acs_46 | 2.032456 .7983213 2.55 0.011 .0549752
full | .609715 .4758205 1.28 0.201 .0637969
emer | -.7066192 .6054086 -1.17 0.244 -.0580132
enroll | -.012164 .0167921 -0.72 0.469 -.0193554
_cons | 778.8305 61.68663 12.63 0.000 .
------------------------------------------------------------------------------
Because the coefficients in the Beta column are all in the same standardized units you can compare these coefficients to assess the relative strength of each of the predictors. In this example, meals has the largest Beta coefficient, -0.66 (in absolute value), and acs_k3 has the smallest Beta, 0.013. Thus, a one standard deviation increase in meals leads to a 0.66 standard deviation decrease in predicted api00, with the other variables held constant. And, a one standard deviation increase in acs_k3, in turn, leads to a 0.013 standard deviation increase in predicted api00 with the other variables in the model held constant.
In interpreting this output, remember that the difference between the numbers listed in the Coef. column and the Beta column is in the units of measurement. For example, to describe the raw coefficient for ell you would say “A one-unit decrease in ell would yield a .86-unit increase in the predicted api00.” However, for the standardized coefficient (Beta) you would say, “A one standard deviation decrease in ell would yield a .15 standard deviation increase in the predicted api00.”
The listcoef command gives more extensive output regarding standardized coefficients. It is not part of Stata, but you can download it over the internet like this.
search listcoef
and then follow the instructions (see also How can I use the search command to search for programs and get additional help? for more information about using search). Now that we have downloaded listcoef, we can run it like this.
listcoef
regress (N=395): Unstandardized and Standardized Estimates
Observed SD: 142.32844
SD of Error: 56.768104
---------------------------------------------------------------------------
api00 | b t P>|t| bStdX bStdY bStdXY SDofX
---------+-----------------------------------------------------------------
ell | -0.86007 -4.083 0.000 -21.2891 -0.0060 -0.1496 24.7527
meals | -2.94822 -17.307 0.000 -94.0364 -0.0207 -0.6607 31.8960
yr_rnd | -19.88875 -2.148 0.032 -8.4174 -0.1397 -0.0591 0.4232
mobility | -1.30135 -2.983 0.003 -9.7692 -0.0091 -0.0686 7.5069
acs_k3 | 1.31870 0.585 0.559 1.8117 0.0093 0.0127 1.3738
acs_46 | 2.03246 2.546 0.011 7.8245 0.0143 0.0550 3.8498
full | 0.60972 1.281 0.201 9.0801 0.0043 0.0638 14.8924
emer | -0.70662 -1.167 0.244 -8.2569 -0.0050 -0.0580 11.6851
enroll | -0.01216 -0.724 0.469 -2.7548 -0.0001 -0.0194 226.4732
---------------------------------------------------------------------------
Let us compare the regress output with the listcoef output. You will notice that the values listed in the Coef., t, and P>|t| values are the same in the two outputs. The values listed in the Beta column of the regress output are the same as the values in the bStadXY column of listcoef. The bStdX column gives the unit change in Y expected with a one standard deviation change in X. The bStdY column gives the standard deviation change in Y expected with a one unit change in X. The SDofX column gives that standard deviation of each predictor variable in the model.
For example, the bStdX for ell is -21.3, meaning that a one standard deviation increase in ell would lead to an expected 21.3 unit decrease in api00. The bStdY value for ell of -0.0060 means that for a one unit, one percent, increase in english language learners, we would expect a 0.006 standard deviation decrease in api00. Because the bStdX values are in standard units for the predictor variables, you can use these coefficients to compare the relative strength of the predictors like you would compare Beta coefficients. The difference is BStdX coefficients are interpreted as changes in the units of the outcome variable instead of in standardized units of the outcome variable. For example, the BStdX for meals versus ell is -94 versus -21, or about 4 times as large, the same ratio as the ratio of the Beta coefficients. We have created an annotated output that more thoroughly explains the output from listcoef.
So far, we have concerned ourselves with testing a single variable at a time, for example looking at the coefficient for ell and determining if that is significant. We can also test sets of variables, using the test command, to see if the set of variables are significant. First, let’s start by testing a single variable, ell, using the test command.
test ell==0
( 1) ell = 0.0
F( 1, 385) = 16.67
Prob > F = 0.0001
If you compare this output with the output from the last regression you can see that the result of the F-test, 16.67, is the same as the square of the result of the t-test in the regression (-4.083^2 = 16.67). Note that you could get the same results if you typed the following since Stata defaults to comparing the term(s) listed to 0.
test ell
( 1) ell = 0.0
F( 1, 385) = 16.67
Prob > F = 0.0001
Perhaps a more interesting test would be to see if the contribution of class size is significant. Since the information regarding class size is contained in two variables, acs_k3 and acs_46, we include both of these with the test command.
test acs_k3 acs_46
( 1) acs_k3 = 0.0
( 2) acs_46 = 0.0
F( 2, 385) = 3.95
Prob > F = 0.0200
The significant F-test, 3.95, means that the collective contribution of these two variables is significant. One way to think of this, is that there is a significant difference between a model with acs_k3 and acs_46 as compared to a model without them, i.e., there is a significant difference between the “full” model and the “reduced” models.
Finally, as part of doing a multiple regression analysis you might be interested in seeing the correlations among the variables in the regression model. You can do this with the correlate command as shown below.
correlate api00 ell meals yr_rnd mobility acs_k3 acs_46 full emer enroll
(obs=395)
| api00 ell meals yr_rnd mobility acs_k3 acs_46
-------------+---------------------------------------------------------------
api00 | 1.0000
ell | -0.7655 1.0000
meals | -0.9002 0.7711 1.0000
yr_rnd | -0.4831 0.5104 0.4247 1.0000
mobility | -0.2106 -0.0149 0.2207 0.0321 1.0000
acs_k3 | 0.1712 -0.0553 -0.1888 0.0222 0.0397 1.0000
acs_46 | 0.2340 -0.1743 -0.2137 -0.0419 0.1280 0.2708 1.0000
full | 0.5759 -0.4867 -0.5285 -0.4045 0.0235 0.1611 0.1212
emer | -0.5902 0.4824 0.5402 0.4401 0.0612 -0.1111 -0.1283
enroll | -0.3221 0.4149 0.2426 0.5920 0.1007 0.1084 0.0281
| full emer enroll
-------------+---------------------------
full | 1.0000
emer | -0.9059 1.0000
enroll | -0.3384 0.3417 1.0000
If we look at the correlations with api00, we see meals and ell have the two strongest correlations with api00. These correlations are negative, meaning that as the value of one variable goes down, the value of the other variable tends to go up. Knowing that these variables are strongly associated with api00, we might predict that they would be statistically significant predictor variables in the regression model.
We can also use the pwcorr command to do pairwise correlations. The most important difference between correlate and pwcorr is the way in which missing data is handled. With correlate, an observation or case is dropped if any variable has a missing value, in other words, correlate uses listwise , also called casewise, deletion. pwcorr uses pairwise deletion, meaning that the observation is dropped only if there is a missing value for the pair of variables being correlated. Two options that you can use with pwcorr, but not with correlate, are the sig option, which will give the significance levels for the correlations and the obs option, which will give the number of observations used in the correlation. Such an option is not necessary with corr as Stata lists the number of observations at the top of the output.
pwcorr api00 ell meals yr_rnd mobility acs_k3 acs_46 full emer enroll, obs sig
| api00 ell meals yr_rnd mobility acs_k3 acs_46
-------------+---------------------------------------------------------------
api00 | 1.0000
|
| 400
|
ell | -0.7676 1.0000
| 0.0000
| 400 400
|
meals | -0.9007 0.7724 1.0000
| 0.0000 0.0000
| 400 400 400
|
yr_rnd | -0.4754 0.4979 0.4185 1.0000
| 0.0000 0.0000 0.0000
| 400 400 400 400
|
mobility | -0.2064 -0.0205 0.2166 0.0348 1.0000
| 0.0000 0.6837 0.0000 0.4883
| 399 399 399 399 399
|
acs_k3 | 0.1710 -0.0557 -0.1880 0.0227 0.0401 1.0000
| 0.0006 0.2680 0.0002 0.6517 0.4245
| 398 398 398 398 398 398
|
acs_46 | 0.2329 -0.1733 -0.2131 -0.0421 0.1277 0.2708 1.0000
| 0.0000 0.0005 0.0000 0.4032 0.0110 0.0000
| 397 397 397 397 396 395 397
|
full | 0.5744 -0.4848 -0.5276 -0.3977 0.0252 0.1606 0.1177
| 0.0000 0.0000 0.0000 0.0000 0.6156 0.0013 0.0190
| 400 400 400 400 399 398 397
|
emer | -0.5827 0.4722 0.5330 0.4347 0.0596 -0.1103 -0.1245
| 0.0000 0.0000 0.0000 0.0000 0.2348 0.0277 0.0131
| 400 400 400 400 399 398 397
|
enroll | -0.3182 0.4030 0.2410 0.5918 0.1050 0.1089 0.0283
| 0.0000 0.0000 0.0000 0.0000 0.0360 0.0298 0.5741
| 400 400 400 400 399 398 397
|
| full emer enroll
-------------+---------------------------
full | 1.0000
|
| 400
|
emer | -0.9057 1.0000
| 0.0000
| 400 400
|
enroll | -0.3377 0.3431 1.0000
| 0.0000 0.0000
| 400 400 400
|
1.5 Transforming Variables
Earlier we focused on screening your data for potential errors. In the next chapter, we will focus on regression diagnostics to verify whether your data meet the assumptions of linear regression. Here, we will focus on the issue of normality. Some researchers believe that linear regression requires that the outcome (dependent) and predictor variables be normally distributed. We need to clarify this issue. In actuality, it is the residuals that need to be normally distributed. In fact, the residuals need to be normal only for the t-tests to be valid. The estimation of the regression coefficients do not require normally distributed residuals. As we are interested in having valid t-tests, we will investigate issues concerning normality.
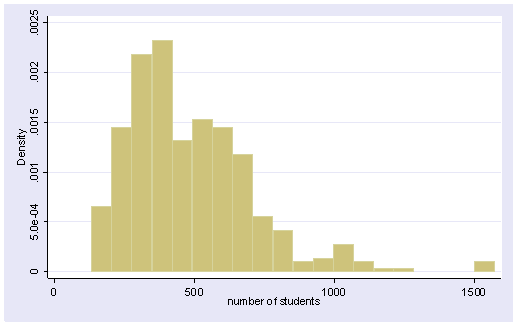
A common cause of non-normally distributed residuals is non-normally distributed outcome and/or predictor variables. So, let us explore the distribution of our variables and how we might transform them to a more normal shape. Let’s start by making a histogram of the variable enroll, which we looked at earlier in the simple regression.
histogram enroll
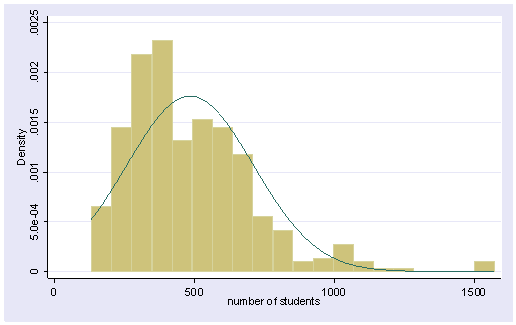
We can use the normal option to superimpose a normal curve on this graph and the bin(20) option to use 20 bins. The distribution looks skewed to the right.
histogram enroll, normal bin(20)
You may also want to modify labels of the axes. For example, we use the xlabel() option for labeling the x-axis below, labeling it from 0 to 1600 incrementing by 100.
histogram enroll, normal bin(20) xlabel(0(100)1600)
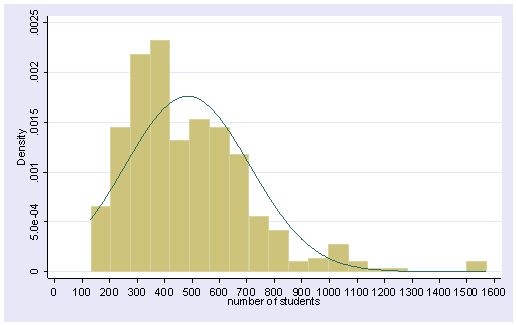
Histograms are sensitive to the number of bins or columns that are used in the display. An alternative to histograms is the kernel density plot, which approximates the probability density of the variable. Kernel density plots have the advantage of being smooth and of being independent of the choice of origin, unlike histograms. Stata implements kernel density plots with the kdensity command.
kdensity enroll, normal
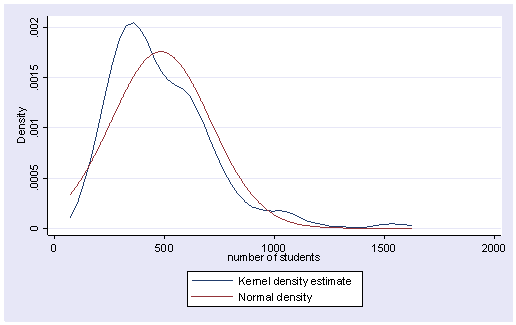
Not surprisingly, the kdensity plot also indicates that the variable enroll does not look normal. Now let’s make a boxplot for enroll, using graph box command.
graph box enroll
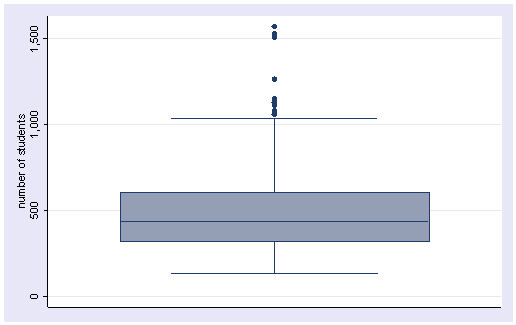
Note the dots at the top of the boxplot which indicate possible outliers, that is, these data points are more than 1.5*(interquartile range) above the 75th percentile. This boxplot also confirms that enroll is skewed to the right.
There are three other types of graphs that are often used to examine the distribution of variables; symmetry plots, normal quantile plots and normal probability plots.
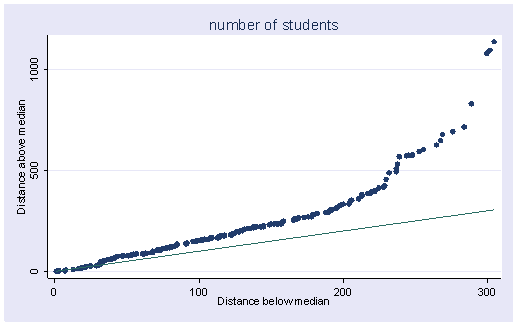
A symmetry plot graphs the distance above the median for the i-th value against the distance below the median for the i-th value. A variable that is symmetric would have points that lie on the diagonal line. As we would expect, this distribution is not symmetric.
symplot enroll
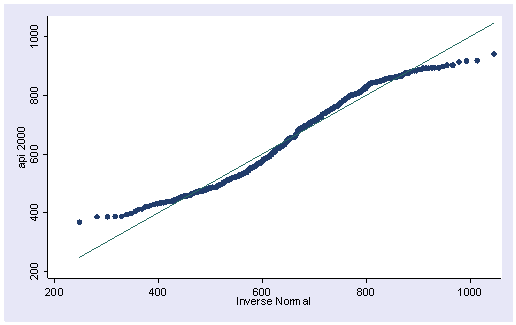
A normal quantile plot graphs the quantiles of a variable against the quantiles of a normal (Gaussian) distribution. qnorm is sensitive to non-normality near the tails, and indeed we see considerable deviations from normal, the diagonal line, in the tails. This plot is typical of variables that are strongly skewed to the right.
qnorm api00
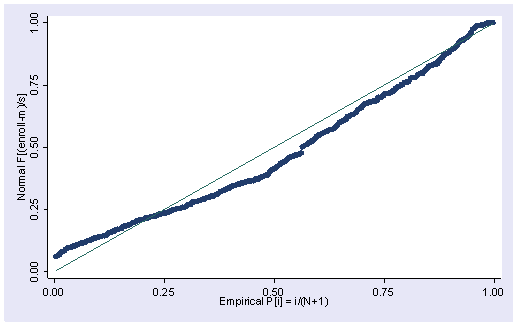
Finally, the normal probability plot is also useful for examining the distribution of variables. pnorm is sensitive to deviations from normality nearer to the center of the distribution. Again, we see indications of non-normality in enroll.
pnorm enroll
Having concluded that enroll is not normally distributed, how should we address this problem? First, we may try entering the variable as-is into the regression, but if we see problems, which we likely would, then we may try to transform enroll to make it more normally distributed. Potential transformations include taking the log, the square root or raising the variable to a power. Selecting the appropriate transformation is somewhat of an art. Stata includes the ladder and gladder commands to help in the process. Ladder reports numeric results and gladder produces a graphic display. Let’s start with ladder and look for the transformation with the smallest chi-square.
ladder enroll ladder enroll Transformation formula chi2(2) P(chi2) ------------------------------------------------------------------ cube enroll^3 . 0.000 square enroll^2 . 0.000 raw enroll . 0.000 square-root sqrt(enroll) 20.56 0.000 log log(enroll) 0.71 0.701 reciprocal root 1/sqrt(enroll) 23.33 0.000 reciprocal 1/enroll 73.47 0.000 reciprocal square 1/(enroll^2) . 0.000 reciprocal cube 1/(enroll^3) . 0.000
The log transform has the smallest chi-square. Let’s verify these results graphically using gladder.
gladder enroll
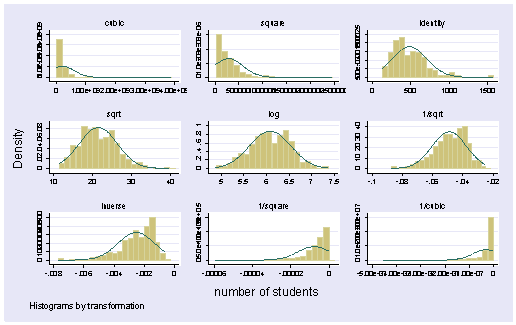
This also indicates that the log transformation would help to make enroll more normally distributed. Let’s use the generate command with the log function to create the variable lenroll which will be the log of enroll. Note that log in Stata will give you the natural log, not log base 10. To get log base 10, type log10(var).
generate lenroll = log(enroll)
Now let’s graph our new variable and see if we have normalized it.
hist lenroll, normal
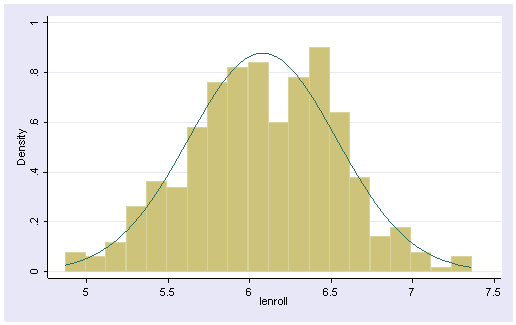
We can see that lenroll looks quite normal. We would then use the symplot, qnorm and pnorm commands to help us assess whether lenroll seems normal, as well as seeing how lenroll impacts the residuals, which is really the important consideration.
1.6 Summary
In this lecture we have discussed the basics of how to perform simple and multiple regressions, the basics of interpreting output, as well as some related commands. We examined some tools and techniques for screening for bad data and the consequences such data can have on your results. Finally, we touched on the assumptions of linear regression and illustrated how you can check the normality of your variables and how you can transform your variables to achieve normality. The next chapter will pick up where this chapter has left off, going into a more thorough discussion of the assumptions of linear regression and how you can use Stata to assess these assumptions for your data. In particular, the next lecture will address the following issues.
- Checking for points that exert undue influence on the coefficients
- Checking for constant error variance (homoscedasticity)
- Checking for linear relationships
- Checking model specification
- Checking for multicollinearity
- Checking normality of residuals
1.7 Self Assessment
- Make five graphs of api99: histogram, kdensity plot, boxplot, symmetry plot and normal quantile plot.
- What is the correlation between api99 and meals?
- Regress api99 on meals. What does the output tell you?
- Create and list the fitted (predicted) values.
- Graph meals and api99 with and without the regression line.
- Look at the correlations among the variables api99 meals ell avg_ed using the corr and pwcorr commands. Explain how these commands are different. Make a scatterplot matrix for these variables and relate the correlation results to the scatterplot matrix.
- Perform a regression predicting api99 from meals and ell. Interpret the output.
Click here for our answers to these self assessment questions.
1.8 For More Information
- Stata Manuals
- [R] regress
- [R] predict
- [R] test
- Related Web Pages
- Stata Add On Programs