Chapter Outline
6.0 Introduction
6.1. Analysis with two categorical variables
6.2. Simple effects
6.2.1 Analyzing simple effects using PROC GLM
6.2.2 Analyzing Simple Effects Using PROC REG
6.3. Simple comparisons
6.3.1 Analyzing simple comparisons using PROC REG
6.3.2 Analyzing simple comparisons using PROC GLM
6.4. Partial Interaction
6.4.1 Analyzing partial interactions using PROC GLM
6.4.2 Analyzing partial interactions using PROC REG
6.5. Interaction contrasts
6.5.1 Analyzing interaction contrasts using PROC GLM
6.5.2 Analyzing interaction contrasts using PROC REG
6.6. Computing adjusted means
6.6.1 Computing adjusted means via PROC GLM
6.6.1 Computing adjusted means via PROC REG
6.7. More details on meaning of coefficients
6.8. Simple effects via dummy coding versus effect coding
6.8.1 Example 1. Simple effects of yr_rnd at levels of mealcat
6.8.2 Example 2. Simple effects of mealcat at levels of yr_rnd
6.0 Introduction
This chapter will use the elemapi2 data that you have seen in the prior chapters. We assume that you have put the data files in "c:sasreg" directory.
data elemapi2; set 'c:sasregelemapi2'; run;
For this chapter we will use the elemapi2 data file that we have been using in prior chapters. We will focus on the variables mealcat, and collcat as they relate to the outcome variable api00 (performance on the api in the year 2000. The variable mealcat is the variable meals broken up into three categories, and the variable collcat is the variable some_col broken into 3 categories. We could think of mealcat as being the number of students receiving free meals and broken up into low, middle and high. The variable collcat can be thought of as the number of parents with some college education, and we could think of it as being broken up into low, medium and high. For our analysis, we think that both mealcat and collcat may be related to api00, but it is also possible that the impact of mealcat might depend on the level of collcat. In other words, we think that there might be an interaction of these two categorical variables. In this chapter we will look at how these two categorical variables are related to api performance in the school, and we will look at the interaction of these two categorical variables as well. We will see that there is an interaction of these categorical variables, and will focus on different ways of further exploring the interaction. Let’s have a quick look at these variables.
proc tabulate data=elemapi2;
class collcat mealcat ;
var api00;
table mealcat='mealcat',
mean=' '*api00='API Index for 2000'*collcat='collcat'*F=10.2
/ RTS=13.;
run;
----------------------------------------------
| | API Index for 2000 |
| |--------------------------------|
| | collcat |
| |--------------------------------|
| | 1 | 2 | 3 |
|-----------+----------+----------+----------|
|mealcat | | | |
|-----------| | | |
|1 | 816.91| 825.65| 782.15|
|-----------+----------+----------+----------|
|2 | 589.35| 636.60| 655.64|
|-----------+----------+----------+----------|
|3 | 493.92| 508.83| 541.73|
----------------------------------------------
6.1. Analysis with two categorical variables
One traditional way to analyze this would be to perform a 3 by 3 factorial analysis of variance using proc glm, as shown below. The results show a main effect of collcat (F=4.5, p-0.0117), a main effect of mealcat (F=509.04, p=0.0000) and an interaction of collcat by mealcat, (F=6.63, p=0.0000). We also use lsmeans and output statement to output the predicted means for each group and get ourselve ready to graph the cell means.
proc glm data = elemapi2; class collcat mealcat; model api00 = collcat | mealcat /ss3; lsmeans collcat*mealcat; output out = pred p = pred; run; quit;
The GLM Procedure
Class Level Information
Class Levels Values
collcat 3 1 2 3
mealcat 3 1 2 3
Number of observations 400
The GLM Procedure
Dependent Variable: api00 api 2000
Sum of
Source DF Squares Mean Square F Value Pr > F
Model 8 6243714.810 780464.351 166.76 <.0001
Error 391 1829957.187 4680.197
Corrected Total 399 8073671.998
R-Square Coeff Var Root MSE api00 Mean
0.773343 10.56356 68.41197 647.6225
Source DF Type III SS Mean Square F Value Pr > F
collcat 2 42140.566 21070.283 4.50 0.0117
mealcat 2 4764843.563 2382421.781 509.04 <.0001
collcat*mealcat 4 124167.809 31041.952 6.63 <.0001
Least Squares Means
collcat mealcat api00 LSMEAN
1 1 816.914286
1 2 589.350000
1 3 493.918919
2 1 825.651163
2 2 636.604651
2 3 508.833333
3 1 782.150943
3 2 655.637681
3 3 541.733333
We can now create the graph of cell means of api00 using the dataset pred.
proc sort data = pred; by mealcat; run;symbol1 v=circle i=join ci=blue h= 2; symbol2 v=triangle i=join ci=red h =2; symbol3 v=square i=join ci=black h =2;proc gplot data = pred; plot pred*mealcat=collcat ; run; quit;
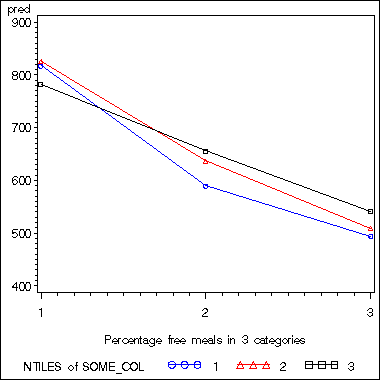
We can do the same analysis using the regression approach via proc reg. We use simple regression coding for both collcat and mealcat. We also create interaction terms for them. The first test statement tests the effect of main effect of collcat, the second the main effect of mealcat and the last one on the effect of overall interaction.
data reg1; set elemapi2; s2 = -1/3; s3=-1/3; if collcat = 2 then s2 = 2/3; if collcat = 3 then s3 = 2/3; m2 = -1/3; m3 = -1/3; if mealcat = 2 then m2 = 2/3; if mealcat = 3 then m3 = 2/3; sm22 = s2*m2; sm23 = s2*m3; sm32 = s3*m2; sm33 = s3*m3; run; proc reg data = reg1; model api00 = s2 s3 m2 m3 sm22 sm23 sm32 sm33; Collcat: test s2=s3=0; Mealcat: test m2=m3=0; Interaction: test sm22=sm23=sm32=sm33=0; output out = pred2 p = pred; run; quit;
The REG Procedure
Model: MODEL1
Dependent Variable: api00 api 2000
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 8 6243715 780464 166.76 <.0001
Error 391 1829957 4680.19741
Corrected Total 399 8073672
Root MSE 68.41197 R-Square 0.7733
Dependent Mean 647.62250 Adj R-Sq 0.7687
Coeff Var 10.56356
Parameter Estimates
Parameter Standard
Variable Label DF Estimate Error t Value Pr > |t|
Intercept Intercept 1 650.08826 3.87189 167.90 <.0001
s2 1 23.63531 9.10533 2.60 0.0098
s3 1 26.44625 9.99513 2.65 0.0085
m2 1 -181.04135 9.07713 -19.94 <.0001
m3 1 -293.41027 9.44946 -31.05 <.0001
sm22 1 38.51777 24.19532 1.59 0.1122
sm23 1 6.17754 20.08262 0.31 0.7585
sm32 1 101.05102 22.88808 4.42 <.0001
sm33 1 82.57776 24.43941 3.38 0.0008
Test Collcat Results for Dependent Variable API00
Mean
Source DF Square F Value Pr > F
Numerator 2 21070 4.50 0.0117
Denominator 391 4680.19741
Test Mealcat Results for Dependent Variable API00
Mean
Source DF Square F Value Pr > F
Numerator 2 2382422 509.04 <.0001
Denominator 391 4680.19741
Test Interaction Results for Dependent Variable API00
Mean
Source DF Square F Value Pr > F
Numerator 4 31042 6.63 <.0001
Denominator 391 4680.19741
First, note that the results of the test statements correspond to those from proc glm statement. This is because collcat and mealcat were coded using simple effect coding, a coding scheme where the contrasts sum to 0. If this had been coded using dummy coding, then the results of the test commands for mealcat and collcat from the proc reg would not have corresponded to the proc glm results. In addition to simple coding, we could have used deviation or helmert coding schemes and the results of the test commands would have matched the result from proc glm, although the meaning of the individual tests would have been different. This point will be explored in more detail later in this chapter.
The graph of the cell means we obtained before illustrates the interaction between collcat and mealcat. The graph shows the 3 levels of collcat as 3 different lines, and the 3 levels of mealcat as the 3 values on the x axis of the graph. We can see that the effect of collcat differs based on the level of mealcat. For example, when mealcat is low, schools where collcat is 3 have the lowest api00 scores, as compared to schools that are medium or high on mealcat, where schools with collcat of 3 have the highest api00 scores.
Let’s investigate this interaction further by looking at the simple effects of collcat at each level of mealcat.
6.2. Simple effects
6.2.1 Analyzing simple effects using PROC GLM
This analysis looks at the simple effects of collcat at the different levels of mealcat using proc glm. The lsmeans statement with option slice = mealcat gives the test of effects of collcat at each level of mealcat.
proc glm data= elemapi2; class collcat mealcat; model api00 = mealcat|collcat ; lsmeans mealcat*collcat / slice = mealcat ; run; quit;
The GLM Procedure
Sum of
Source DF Squares Mean Square F Value Pr > F
Model 8 6243714.810 780464.351 166.76 <.0001
Error 391 1829957.187 4680.197
Corrected Total 399 8073671.998
R-Square Coeff Var Root MSE API00 Mean
0.773343 10.56356 68.41197 647.6225
Source DF Type III SS Mean Square F Value Pr > F
MEALCAT 2 4764843.563 2382421.781 509.04 <.0001
COLLCAT 2 42140.566 21070.283 4.50 0.0117
COLLCAT*MEALCAT 4 124167.809 31041.952 6.63 <.0001
COLLCAT MEALCAT API00 LSMEAN
1 1 816.914286
1 2 589.350000
1 3 493.918919
2 1 825.651163
2 2 636.604651
2 3 508.833333
3 1 782.150943
3 2 655.637681
3 3 541.733333
COLLCAT*MEALCAT Effect Sliced by MEALCAT for API00
Sum of
MEALCAT DF Squares Mean Square F Value Pr > F
1 2 50909 25455 5.44 0.0047
2 2 68629 34314 7.33 0.0007
3 2 29979 14990 3.20 0.0417
6.2.2 Analyzing Simple Effects Using PROC REG
We have demonstrated how to test the simple effect of collcat at each level of mealcat using PROC GLM in the previous section. That is through the approach of ANOVA. We can also obtain the same analysis through regression approach. After all, Anova is regression. In regression approach, we will create the coding for variable collcat, mealcat and their interaction. The coding scheme is specific for the effect we want to see. For example, in this section, we will do an analysis parallel to the previous section. That is to say that we want to see the simple effect of collcat at each level of mealcat. We will use simple coding for mealcat, though in our case the type of coding for mealcat does not really matter. The scheme for simple coding is shown chapter 5. The reference group for mealcat is group 1. We use helmert coding for collcat. We should note that these terms are not used in the analysis, but are used for creating the simple effects of collcat at each level of mealcat.
data reg2; set elemapi2; mcat1 = 1/3; mcat2 = 1/3; if mealcat = 3 then mcat1 = -2/3; if mealcat = 2 then mcat2 = -2/3; ccat1 = -1/3; if collcat = 1 then do; ccat1 = 2/3; ccat2 = 0; end; if collcat = 2 then ccat2 = .5; if collcat = 3 then ccat2 = -.5; c1m1 = 0; c2m1 = 0; c1m2 = 0; c2m2 = 0; c1m3 = 0; c2m3 = 0;if ( mealcat = 1) then do; c1m1 = ccat1; c2m1 = ccat2; end;if ( mealcat = 2) then do; c1m2 = ccat1; c2m2 = ccat2; end; if ( mealcat = 3) then do; c1m3 = ccat1; c2m3 = ccat2; end; run;
Now, that we have seen the helmert coding for collcat, we can see how this is used to create the simple effects of collcat at each level of mealcat. First, we look at the two comparisons of collcat at mealcat of 1. Note that the coding is the same as we saw above, but only when mealcat is 1, otherwise these variables are coded 0. Likewise, we look at the terms that form the effects of collcat when mealcat is 2, and we see that the variables are coded the same way when mealcat is 2, and otherwise 0. The same is true for the case when mealcat is 3. The following matrix is the coding we just used for all the interaction terms.
| collcat | mealcat | c1m1 | c2m1 | c1m2 | c2m2 | c1m3 | c2m3 |
| 1 | 1 | 2/3 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | -1/3 | 1/2 | 0 | 0 | 0 | 0 |
| 3 | 1 | -1/3 | -1/2 | 0 | 0 | 0 | 0 |
| 1 | 2 | 0 | 0 | 2/3 | 0 | 0 | 0 |
| 2 | 2 | 0 | 0 | -1/3 | 1/2 | 0 | 0 |
| 3 | 2 | 0 | 0 | -1/3 | -1/2 | 0 | 0 |
| 1 | 3 | 0 | 0 | 0 | 0 | 2/3 | 0 |
| 2 | 3 | 0 | 0 | 0 | 0 | -1/3 | 1/2 |
| 3 | 3 | 0 | 0 | 0 | 0 | -1/3 | -1/2 |
Now we are ready for our regression analysis. The test statements used below are for testing the simple effect of collcat at each level of mealcat.
proc reg data = reg2; model api00 = mcat1 mcat2 c1m1 c2m1 c1m2 c2m2 c1m3 c2m3; mealcat1: test c1m1 = c2m1 = 0; mealcat2: test c1m2 = c2m2 = 0; mealcat3: test c1m3 = c2m3 = 0; run; quit;
The REG Procedure Model: MODEL1 Dependent Variable: API00 api 2000
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 8 6243715 780464 166.76 <.0001
Error 391 1829957 4680.19741
Corrected Total 399 8073672
Root MSE 68.41197 R-Square 0.7733
Dependent Mean 647.62250 Adj R-Sq 0.7687
Coeff Var 10.56356
Parameter Estimates
Parameter Standard
Variable Label DF Estimate Error t Value Pr > |t|
Intercept Intercept 1 650.08826 3.87189 167.90 <.0001
MCAT1 1 293.41027 9.44946 31.05 <.0001
MCAT2 1 181.04135 9.07713 19.94 <.0001
C1M1 1 13.01323 13.52800 0.96 0.3367
C2M1 1 43.50022 14.04092 3.10 0.0021
C1M2 1 -56.77117 16.67866 -3.40 0.0007
C2M2 1 -19.03303 13.29175 -1.43 0.1530
C1M3 1 -31.36441 12.86955 -2.44 0.0153
C2M3 1 -32.90000 20.23653 -1.63 0.1048
Test mealcat1 Results for Dependent Variable API00
Mean
Source DF Square F Value Pr > F
Numerator 2 25455 5.44 0.0047
Denominator 391 4680.19741
Test mealcat2 Results for Dependent Variable API00
Mean
Source DF Square F Value Pr > F
Numerator 2 34314 7.33 0.0007
Denominator 391 4680.19741
Test mealcat3 Results for Dependent Variable API00
Mean
Source DF Square F Value Pr > F
Numerator 2 14990 3.20 0.0417
Denominator 391 4680.19741
6.3 Simple Comparisons
In the analyses above we looked at the simple effect of collcat at each level of mealcat. For example, we looked at the overall effect of collcat when mealcat was 1. This is the simple effect of collcat at mealcat=1. Because collcat has more than 2 levels, we may wish to make further comparisons among the 3 levels of collcat within mealcat=1. Simple comparisons allow us to make such comparisons.
6.3.1 Analyzing Simple Comparisons Using PROC REG
In the previous regression analysis, we used helmert coding for collcat. We choose this coding scheme so we could compare group 1 with groups 2 and 3 and then compare groups 2 and 3 within mealcat = 1. For example, if we wanted to compare collcat 1 vs. 2 and 3, we would want to look at the effect c1m1, and if we wanted to compare collcat groups 2 and 3 when mealcat is 1, then we would look at the effect c2m1. For example, c1m1 is not significant with t-value = 0.96 and p-value = 0.3367. That is to say that the difference between group 1 of collcat with group 2 and group 3 with mealcat = 1 is not significant.
6.3.2 Analyzing Simple Comparisons Using PROC GLM
We can also look at the simple comparisons using PROC GLM. For example, for the comparsion of group 1 vs 2+ of collcat within mealcat = 1, we can do the following. The estimate statement below indicates that the comparison on collcat is between group 1 and all the upper groups and the comparison is restricted to within mealcat = 1.
proc glm data = elemapi2;
class collcat mealcat;
model api00 = collcat mealcat collcat*mealcat/ss3;
estimate 'collcat 1 vs 2+ within mealcat = 1'
collcat 1 -.5 -.5
collcat*mealcat 1 0 0
-.5 0 0
-.5 0 0;
run;
quit;
The GLM Procedure
Dependent Variable: API00 api 2000
Sum of
Source DF Squares Mean Square F Value Pr > F
Model 8 6243714.810 780464.351 166.76 <.0001
Error 391 1829957.187 4680.197
Corrected Total 399 8073671.998
R-Square Coeff Var Root MSE API00 Mean
0.773343 10.56356 68.41197 647.6225
Source DF Type III SS Mean Square F Value Pr > F
COLLCAT 2 42140.566 21070.283 4.50 0.0117
MEALCAT 2 4764843.563 2382421.781 509.04 <.0001
COLLCAT*MEALCAT 4 124167.809 31041.952 6.63 <.0001
Standard
Parameter Estimate Error t Value Pr > |t|
collcat 1 vs 2+ within mealcat = 1 13.0132326 13.5279998 0.96 0.3367
6.4 Partial Interaction
A partial interaction allows you to apply contrasts to one of the effects in an interaction term. For example, we can draw the interaction of collcat by mealcat like this below.
| Collcat low | Collcat Med | Collcat High | |
| Mealcat Low | |||
| Mealcat Med | |||
| Mealcat High |
Say that we wanted to compare, in the context of this interaction, group 1 for collcat vs. groups 2 and 3. The table of this partial interaction would look like this. The contrast coefficients of -2 1 1 applied to collcat indicate the comparison of group 1 for collcat vs. groups 2 and 3.
| -2 | 1 | 1 | |
| Collcat low | Collcat Med | Collcat High | |
| Mealcat Low | |||
| Mealcat Med | |||
| Mealcat High |
Likewise, we also might want to compare groups 2 and 3 of collcat by mealcat, and the table of this interaction would look like this.
| 0 | -1 | 1 | |
| Collcat low | Collcat Med | Collcat High | |
| Mealcat Low | |||
| Mealcat Med | |||
| Mealcat High |
These are called partial interactions because contrast coefficients are applied to one of the terms involved in the interaction.
6.4.1 Analyzing partial interactions using PROC GLM
We wish to compare groups 1 versus 2 on collcat. Similarly, we can also compare groups 2 and 3 on collcat.
For example, we want to test the partial interaction of collcat comparing group 1 vs. 2 and 3 by mealcat, we can do the following contrast statement. Because mealcat has 2 degrees of freedom, the test of partial interaction also has 2 degrees of freedom. The 2 degrees of freedom of factor mealcat can be broken down into 2 comparisons. These two interaction contrasts are separated by a semi-colon, which tells SAS to join these contrasts together into a single test with 2 degrees of freedom.
proc glm data = elemapi2;
class collcat mealcat;
model api00 = collcat mealcat collcat*mealcat;
contrast 'test of sm11 and sm12' collcat*mealcat 1 -1 0
-.5 .5 0
-.5 .5 0,
collcat*mealcat 0 1 -1
0 -.5 .5
0 -.5 .5;
contrast 'test of sm21 and sm22' collcat*mealcat 0 0 0
1 -1 0
-1 1 0,
collcat*mealcat 0 0 0
0 1 -1
0 -1 1;
run;
quit;
The GLM Procedure <output omitted> Contrast DF Contrast SS Mean Square F Value Pr > F test of sm11 and sm12 2 54141.40962 27070.70481 5.78 0.0033 test of sm21 and sm22 2 66511.60133 33255.80067 7.11 0.0009
6.4.2 Analyzing partial interactions Using
PROC REG
With regression analysis, we can also compare groups 1 vs. 2 and 3 on collcat, or compare groups 2 and 3 on collcat. This implies Helmert coding on collcat, as we did before.
data reg3; set elemapi2; if mealcat = 1 then m1 = 2/3; if mealcat = 2 then m1 = -1/3; if mealcat = 3 then m1 = -1/3; if mealcat = 1 then m2 = 1/3; if mealcat = 2 then m2 = 1/3; if mealcat = 3 then m2 = -2/3; if collcat = 1 then s1 = 2/3; if collcat = 2 then s1 = -1/3; if collcat = 3 then s1 = -1/3; if collcat = 1 then s2 = 0; if collcat = 2 then s2 = 1/2; if collcat = 3 then s2 = -1/2; sm11 = s1*m1; sm12 = s1*m2; sm21 = s2*m1; sm22 = s2*m2; run; proc reg data = reg3; model api00 = s1 s2 m1 m2 sm11 sm12 sm21 sm22; test sm11 = sm12 = 0; test sm21 = sm22 = 0; run; quit;
The REG Procedure
Model: MODEL1
Dependent Variable: api00 api 2000
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 8 6243715 780464 166.76 <.0001
Error 391 1829957 4680.19741
Corrected Total 399 8073672
Root MSE 68.41197 R-Square 0.7733
Dependent Mean 647.62250 Adj R-Sq 0.7687
Coeff Var 10.56356
Parameter Estimates
Parameter Standard
Variable Label DF Estimate Error t Value Pr > |t|
Intercept Intercept 1 650.08826 3.87189 167.90 <.0001
s1 1 -25.04078 8.34539 -3.00 0.0029
s2 1 -2.81094 9.32938 -0.30 0.7633
m1 1 181.04135 9.07713 19.94 <.0001
m2 1 112.36892 9.90759 11.34 <.0001
sm11 1 69.78440 21.47520 3.25 0.0013
sm12 1 -25.40675 21.06663 -1.21 0.2285
sm21 1 62.53325 19.33438 3.23 0.0013
sm22 1 13.86697 24.21132 0.57 0.5671
Test 1 Results for Dependent Variable api00
Mean
Source DF Square F Value Pr > F
Numerator 2 27071 5.78 0.0033
Denominator 391 4680.19741
Test 2 Results for Dependent Variable api00
Mean
Source DF Square F Value Pr > F
Numerator 2 33256 7.11 0.0009
Denominator 391 4680.19741
6.5. Interaction Contrasts
Above we saw that a partial interaction allows you to apply contrast coefficients to one of the terms in a 2 way interaction. An interaction contrast allows you to apply contrast coefficients to both of the terms in a two way interaction.
For example, with respect to collcat, let’s say that we wish to compare groups 2 and 3, and with respect to mealcat we wish to compare groups 1 and 2. The table of this looks like this below.
| -1 | 1 | 0 | ||
| Collcat low | Collcat Med | Collcat High | ||
| 0 | Mealcat Low | |||
| -1 | Mealcat Med | |||
| 1 | Mealcat High | |||
We also would like to form a second interaction contrast that also compares groups 2 and 3 with respect to collcat, and compares groups 2 and 3 on mealcat. A table of this comparison is shown below.
| 0 | -1 | 1 | ||
| Collcat low | Collcat Med | Collcat High | ||
| 0 | Mealcat Low | |||
| -1 | Mealcat Med | |||
| 1 | Mealcat High | |||
If we look at the graph of the predicted values (repeated below) we constructed before, it compares line 2 and 3 (collcat 2 vs. 3) by mealcat 1 vs. 2, and then again by mealcat 2 vs. 3.
6.5.1 Analyzing Interaction Contrasts Using PROG GLM
proc glm data = elemapi2;
class collcat mealcat;
model api00 = collcat mealcat collcat*mealcat;
contrast 'collcat 2v3 with mealcat 1v2' collcat*mealcat 0 0 0
1 -1 0
-1 1 0;
contrast 'somecat 2v3 with mealcat 2v3' collcat*mealcat 0 0 0
0 1 -1
0 -1 1;
run;
quit;
The GLM Procedure <output omitted> Contrast DF Contrast SS Mean Square F Value collcat 2v3 with mealcat 1v2 1 48958.23687 48958.23687 10.46 somceat 2v3 with mealcat 2v3 1 1535.28987 1535.28987 0.33 Contrast Pr > F collcat 2v3 with mealcat 1v2 0.0013 somceat 2v3 with mealcat 2v3 0.5671
6.5.2 Analyzing interaction contrasts using PROC REG
In regression analysis, we have seen that difference coding schemes of the variables give us difference contrasts and comparisons. Because we would like to compare groups 1 vs. 2, and then groups 2 vs. 3 on mealcat, we will use forward difference coding for mealcat (which will compare 1 vs. 2, then 2 vs. 3).
data reg4; set elemapi2; if mealcat = 1 then m1 = 2/3; if mealcat = 2 then m1 = -1/3; if mealcat = 3 then m1 = -1/3; if mealcat = 1 then m2 = 1/3; if mealcat = 2 then m2 = 1/3; if mealcat = 3 then m2 = -2/3; if collcat = 1 then s1 = 2/3; if collcat = 2 then s1 = -1/3; if collcat = 3 then s1 = -1/3; if collcat = 1 then s2 = 0; if collcat = 2 then s2 = 1/2; if collcat = 3 then s2 = -1/2; sm11 = s1*m1; sm12 = s1*m2; sm21 = s2*m1; sm22 = s2*m2; run; proc reg data = reg4; model api00 = s1 s2 m1 m2 sm11 sm12 sm21 sm22; run; quit;
The REG Procedure
Model: MODEL1
Dependent Variable: api00 api 2000
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 8 6243715 780464 166.76 <.0001
Error 391 1829957 4680.19741
Corrected Total 399 8073672
Root MSE 68.41197 R-Square 0.7733
Dependent Mean 647.62250 Adj R-Sq 0.7687
Coeff Var 10.56356
Parameter Estimates
Parameter Standard
Variable Label DF Estimate Error t Value Pr > |t|
Intercept Intercept 1 650.08826 3.87189 167.90 <.0001
s1 1 -25.04078 8.34539 -3.00 0.0029
s2 1 -2.81094 9.32938 -0.30 0.7633
m1 1 181.04135 9.07713 19.94 <.0001
m2 1 112.36892 9.90759 11.34 <.0001
sm11 1 69.78440 21.47520 3.25 0.0013
sm12 1 -25.40675 21.06663 -1.21 0.2285
sm21 1 62.53325 19.33438 3.23 0.0013
sm22 1 13.86697 24.21132 0.57 0.5671
6.6 Computing Adjusted Means
Our model will be almost the same as before, in addition we include an additional covariate emer. We want to obtain the adjusted means of api00 adjusted for variable emer. These adjusted means compute the mean that would be expected if every school in the sample were at the mean for the variable emer.
6.6.1 Computing Adjusted Means via PROC GLM
The syntax to get the adjusted means using proc glm is as follows. The default is to adjust at the means and it can be changed by using at variable = value option following the lsmeans statement.
proc glm data = elemapi2; class collcat mealcat; model api00 = collcat mealcat collcat*mealcat emer /ss3; lsmeans collcat*mealcat; run; quit;
The GLM Procedure
Sum of
Source DF Squares Mean Square F Value Pr > F
Model 9 6402428.265 711380.918 166.01 <.0001
Error 390 1671243.733 4285.240
Corrected Total 399 8073671.998
R-Square Coeff Var Root MSE api00 Mean
0.793001 10.10801 65.46175 647.6225
Source DF Type III SS Mean Square F Value Pr > F
collcat 2 34730.090 17365.045 4.05 0.0181
mealcat 2 3017331.845 1508665.923 352.06 <.0001
collcat*mealcat 4 96789.116 24197.279 5.65 0.0002
emer 1 158713.455 158713.455 37.04 <.0001
collcat mealcat api00 LSMEAN 1 1 797.560428 1 2 596.972811 1 3 509.872241 2 1 812.550248 2 2 636.404940 2 3 523.884659 3 1 767.935241 3 2 652.976146 3 3 550.461628
6.6.2 Computing Adjusted Means via REGRESSION
Now we illustrate how to get the same adjusted means if you were to to the analysis via the proc reg. First, we need to create all the necessary dummy variables for the categorical variables. The choice of coding schemes does not matter for the purpose of obtaining the adjusted means. We choose the same coding scheme we used before for both mealcat and collcat below. After coding our variables properly, we proceed to proc reg to generate the regression equation used later in the proc score statement to generate predicted valued based on the equation. The proc sql statement below simply generates a new variable meanemer as the mean of emer.
data reg6; set elemapi2; if collcat = 1 then s2 = 2/3; if collcat = 2 then s2 = -1/3; if collcat = 3 then s2 = -1/3; if collcat = 1 then s3 = -1/3; if collcat = 2 then s3 = 2/3; if collcat = 3 then s3 = -1/3; if mealcat = 1 then m2 = 2/3; if mealcat = 2 then m2 = -1/3; if mealcat = 3 then m2 = -1/3; if mealcat = 1 then m3 = -1/3; if mealcat = 2 then m3 = 2/3; if mealcat = 3 then m3 = -1/3; sm22 = s2*m2; sm23 = s2*m3; sm32 = s3*m2; sm33 = s3*m3; run; proc reg data = reg6 outest = pred6 noprint; yhat: model api00 = s2 s3 m2 m3 sm22 sm23 sm32 sm33 emer; run; quit; proc sql; create table xy as select *, mean(emer) as meanemer from reg6; quit;
NOTE: You need to rename meanemer to emer or else the proc score will not work The variables listed on the var statement in the proc score must be the same as the IVs in the regression. If they are not, you get a cryptic message about not finding a variable , even though you can see the variable in the data set.
data xyz; set xy; emer = meanemer; run; proc score data = xyz score = pred6 out = ep type = parms; var s2 s3 m2 m3 sm22 sm23 sm32 sm33 emer; run; proc means data = ep mean; class collcat mealcat; var yhat; run;
The MEANS Procedure
Analysis Variable : yhat
Percentage
free meals
in 3 N
collcat categories Obs Mean
-------------------------------------------
1 1 35 797.5629402
2 20 596.9753239
3 74 509.8747538
2 1 43 812.5527606
2 43 636.4074521
3 48 523.8871715
3 1 53 767.9377531
2 69 652.9786583
3 15 550.4641407
-------------------------------------------
6.7 More Details on Meaning of the Coefficients
So far we have discussed a variety of techniques that you can use to help interpret interactions of categorical variables in regression, but we have not gone into a great detail about the meaning of the coefficients in these analyses. Let’s consider this further. Consider the analysis below using collcat and mealcat, using simple contrasts on both of these variables. The reference group for both variables will be group 1.
data reg7; set elemapi2; if collcat = 1 then s1 = -1/3; if collcat = 2 then s1 = 2/3; if collcat = 3 then s1 = -1/3; if collcat = 1 then s2 = -1/3; if collcat = 2 then s2 = -1/3; if collcat = 3 then s2 = 2/3; if mealcat = 1 then m1 = -1/3; if mealcat = 2 then m1 = 2/3; if mealcat = 3 then m1 = -1/3; if mealcat = 1 then m2 = -1/3; if mealcat = 2 then m2 = -1/3; if mealcat = 3 then m2 = 2/3; sm11 = s1*m1; sm12 = s1*m2; sm21 = s2*m1; sm22 = s2*m2; run; proc reg data = reg7; model api00 = s1 s2 m1 m2 sm11 sm12 sm21 sm22; output out = predreg7 p = yhat; run; quit;
The REG Procedure
Model: MODEL1
Dependent Variable: api00 api 2000
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 8 6243715 780464 166.76 <.0001
Error 391 1829957 4680.19741
Corrected Total 399 8073672
Root MSE 68.41197 R-Square 0.7733
Dependent Mean 647.62250 Adj R-Sq 0.7687
Coeff Var 10.56356
Parameter Estimates
Parameter Standard
Variable Label DF Estimate Error t Value Pr > |t|
Intercept Intercept 1 650.08826 3.87189 167.90 <.0001
s1 1 23.63531 9.10533 2.60 0.0098
s2 1 26.44625 9.99513 2.65 0.0085
m1 1 -181.04135 9.07713 -19.94 <.0001
m2 1 -293.41027 9.44946 -31.05 <.0001
sm11 1 38.51777 24.19532 1.59 0.1122
sm12 1 6.17754 20.08262 0.31 0.7585
sm21 1 101.05102 22.88808 4.42 <.0001
sm22 1 82.57776 24.43941 3.38 0.0008
We can produce the adjusted means as shown below. These will be useful for interpreting the meaning of the coefficients.
proc means data = predreg7 mean; class collcat mealcat; var yhat; run;
The MEANS Procedure
Analysis Variable : yhat Predicted Value of api00
Percentage
free meals
in 3 N
collcat categories Obs Mean
---------------------------------------------------
1 1 35 816.9142857
2 20 589.3500000
3 74 493.9189189
2 1 43 825.6511628
2 43 636.6046512
3 48 508.8333333
3 1 53 782.1509434
2 69 655.6376812
3 15 541.7333333
---------------------------------------------------
Let’s consider the meaning of the coefficient for s1. The coding for this variable compares group 2 vs. group 1, hence this coefficient corresponds to mean(collcat = 2) – mean(collcat = 1). Note that these are the unweighted means, so we compute the mean for collcat = 2 as the mean of the 3 cells corresponding to collcat = 2, i.e. (825.651+636.605+508.833)/3 . If we compare the result below to the coefficient for s1 we see that they are the same,
(825.651+636.605+508.833)/3 – (816.914+589.35+493.919)/3 = 23.635333.
Likewise, the coefficient for s2 is mean(collcat = 3) – mean(collcat = 1), computed below. The value below corresponds to the coefficient for s2.
(782.151+655.638+541.733)/3 – (816.914+589.35+493.919)/3 = 26.446333
Likewise, the coefficient for m1 works out to be mean(mealcat = 2) – mean(mealcat = 1), computed below.
(589.35+636.605+655.638)/3 – (816.914+825.651+782.151)/3 = -181.041.
And the coefficient for m2 is mean(mealcat = 3) – mean(mealcat = 1), computed below.
(493.919+508.833+541.733)/3 – (816.914+825.651+782.151)/3 = -293.41033
To get the meaning of the coefficients for the interaction terms, let’s write out the regression equation and take a closer look at the coefficients. From the parameter estimates, we have the following linear equation for predicted values:
yhat = 650.090 + 23.635*s1 + 26.446*s2
- 181.042*m1 - 293.412*m2
+ 38.518*s1*m1 + 6.178*s1*m2
+ 101.051*s2*m1 + 82.578*s2*m2.
Because of the simple coding scheme we use for both variables, we have from the above equation,
yhat(collcat = 2) – yhat(collcat = 1) = 23.635 + 38.518*ms1 + 6.178*ms2.
One way to think about this equation is that for any level of mealcat comparing group 2 vs. group 1 on collcat only involves s1. It then follows that the coefficient for sm11 is to compare the difference of group 2 vs. 1 on collcat when mealcat is 2 with the difference of group 2 vs. 1 on collcat when mealcat is 1. In other words, sm11 is
[cell(2,2)-cell(1,2)] – [cell(2,1)-cell(1,1)].
Plugging all the corresponding cell means to the above formula, we get
(636.6047 – 589.3500) – (825.6512 – 816.9143) = 38.5175,
which is the coefficient for sm11. Using the same argument, we can have the following
sm11 : [cell(2,2)-cell(1,2)] – [cell(2,1)-cell(1,1)],
sm12 : [cell(2,3)-cell(1,3)] – [cell(2,1)-cell(1,1)],
sm21 : [cell(3,2)-cell(1,2)] – [cell(3,1)-cell(1,1)],
sm22 : [cell(3,3)-cell(1,3)] – [cell(3,1)-cell(1,1)].
We can go through the same process to verify the meaning of the coefficients for the other 3 interaction terms. We verify that sm12 is 6.1775.
(508.8333 – 493.9189) – (825.6512 – 816.9143) = 6.1775.
We also verify that sm21 is 101.051.
(655.6377 – 589.3500) – (782.1509 – 816.9143) = 101.0511.
Last we verify that sm22 is 82.5778.
( 541.7333 – 493.9189) – ( 782.1509 – 816.9143) = 82.5778.
6.8 Simple Effects via Dummy Coding vs. Effect Coding
We have used in this chapter different types of coding schemes. You may wonder why we have gone to the effort of creating and testing these effects instead of just using dummy coding and what is the difference between different coding schemes and how to choose them. In this section, let’s compare how to get simple effects using the effect coding to how we would get simple effects using dummy coding. We hope to show that it is much easier to use effect coding so that the interpretation of the coefficients is much more intuitive.
6.8.1 Example 1. Simple effects of yr_rnd at levels of mealcat
Let’s use an example from Chapter 3 (section 3.5). In that example we looked at and analysis using mealcat and yr_rnd and the interaction of these two variables. First, we look at how to do a simple effects analysis looking at the simple effects of yr_rnd at each level of mealcat using effect coding. To make our results correspond to those from Chapter 3, we will make category 3 of mealcat the reference category.
data reg8; set elemapi2; if mealcat = 1 then do; ms1 =2/3; ms2 = -1/3; end; if mealcat = 2 then do; ms1 =-1/3; ms2= 2/3; end; if mealcat = 3 then do; ms1 =-1/3; ms2 = -1/3; end; if yr_rnd = 0 then yr1 = -1/2; else yr1 = 1/2; ym1 = 0; ym2 = 0; ym3 = 0; if mealcat = 1 then ym1 = yr1; if mealcat = 2 then ym2 = yr1; if mealcat = 3 then ym3 = yr1; run; proc reg data = reg8; model api00 = ms1 ms2 ym1 ym2 ym3; run; quit;
The REG Procedure Model: MODEL1 Dependent Variable: API00 api 2000
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 5 6204728 1240946 261.61 <.0001
Error 394 1868944 4743.51314
Corrected Total 399 8073672
Root MSE 68.87317 R-Square 0.7685
Dependent Mean 647.62250 Adj R-Sq 0.7656
Coeff Var 10.63477
Parameter Estimates
Parameter Standard
Variable Label DF Estimate Error t Value Pr > |t|
Intercept Intercept 1 632.23557 5.80048 109.00 <.0001
MS1 1 267.81076 14.61559 18.32 <.0001
MS2 1 114.65715 11.12812 10.30 <.0001
ym1 1 -74.25691 26.75629 -2.78 0.0058
ym2 1 -51.74017 18.88854 -2.74 0.0064
ym3 1 -33.49254 11.77129 -2.85 0.0047
Now we can obtain the simple effect of yr_rnd at mealcat = 1 by inspecting the coefficient for ym1, the simple effect of yr_rnd at mealcat = 2 by inspecting the coefficient for ym2 and the simple effect of yr_rnd at mealcat = 3 by inspecting the coefficient for ym3.
Now let’s perform the same analysis using dummy coding. Again, we will explicitly make the 3rd category for mealcat to be the omitted category.
data reg9; set elemapi2; if mealcat = 1 then do; md1 = 1; md2 = 0; end; if mealcat = 2 then do; md1 = 0; md2 = 1; end; if mealcat = 3 then do; md1 = 0; md2 = 0; end; ymd1 = yr_rnd*md1; ymd2 = yr_rnd*md2; run;proc reg data = reg9; model api00 = yr_rnd md1 md2 ymd1 ymd2; run;
The REG Procedure
Model: MODEL1
Dependent Variable: API00
Parameter Estimates
Parameter Standard
Variable DF Estimate Error t Value Pr > |t|
Intercept 1 521.49254 8.41420 61.98 <.0001
YR_RND 1 -33.49254 11.77129 -2.85 0.0047
MD1 1 288.19295 10.44284 27.60 <.0001
MD2 1 123.78097 10.55185 11.73 <.0001
ymd1 1 -40.76438 29.23118 -1.39 0.1639
ymd2 1 -18.24763 22.25624 -0.82 0.4128
In order to form a test of simple main effects we need to make a table like the one shown below that relates the cell means to the coefficients in the regression. Please see Chapter 3, section 3.5 for information on how this table was constructed.
mealcat=1
mealcat=2 mealcat=3
————————————————-
yr_rnd=0
const
const
const
+
md1
+ md2
————————————————-
yr_rnd=1
const
const
const
+ yr_rnd
+ yr_rnd + yr_rnd
+
md1
+ md2
+
ymd1
+ ymd2
Let’s start by looking at how to get the simple effect of yr_rnd
when mealcat is 3. Looking at the table above, we can see that we would
want to compare const with const + yr_rnd, , which is the
same as testing the coefficient for yr_rnd is zero. This is a single
parameter test and is shown in the output above. The t-value is -2.85 and the
p-value is .0047.
Note that the coefficient for yr_rnd corresponds to the test of the
effect of yr_rnd when all other variables are set to 0 (the reference
category), i.e. when mealcat is set to the reference category. You may
be tempted to interpret the coefficient for yr_rnd as the overall
difference between year round schools and non-year round schools, but in this
example we see that it really corresponds to the simple effect of yr_rnd.
When using dummy coding people commonly misinterpret the lower order effects
to refer to overall effects rather than simple effects.
Now let’s look at the simple effect of yr_rnd when mealcat=1. Looking at the table above we see that this involves the comparison of the coefficients for yr_rnd=1 vs. yr_rnd=0 when mealcat=1, i.e. comparing const + yr_rnd +md1 + ymd1 vs. const + md1. Removing the terms that drop out we see that to test the simple effect of yr_rnd when mealcat = 1 is the same to test yr_rnd + ymd1 = 0. We will have to do a test statement here following the previous proc reg.
test yr_rnd + ymd1 = 0;
run;
quit;
Test 1 Results for Dependent Variable API00
Mean
Source DF Square F Value Pr > F
Numerator 1 36536 7.70 0.0058
Denominator 394 4743.51314
These examples illustrate that it is more complicated to form simple effects when using dummy coding, and also that the interpretation of lower order effects when using dummy coding may not have the meaning that you would expect.
6.8.2 Example 2. Simple effects of mealcat at levels of yr_rnd
Example 1 looked at simple effects for yr_rnd, a variable with only 2 levels and it showed how to use the test statement in SAS for it. In this example, let’s consider the simple effects of mealcat at each level of yr_rnd. Because mealcat has more than 2 levels, we will see what is required for doing tests of simple effects for variables with more than 2 levels. We will show both proc glm and proc reg approach here.
proc glm data = elemapi2;
class yr_rnd mealcat;
model api00 = yr_rnd mealcat yr_rnd*mealcat;
contrast '1' mealcat 1 0 -1
yr_rnd*mealcat 1 0 -1
0 0 0,
mealcat 0 1 -1
yr_rnd*mealcat 0 1 -1
0 0 0;
contrast '2' mealcat 1 0 -1
yr_rnd*mealcat 0 0 0
1 0 -1,
mealcat 0 1 -1
yr_rnd*mealcat 0 0 0
0 1 -1;
run;
quit;
The GLM Procedure <output omitted>
Contrast DF Contrast SS Mean Square F Value Pr > F 1 2 3903569.804 1951784.902 411.46 <.0001 2 2 476157.455 238078.727 50.19 <.0001
Here is how to do it with proc reg. The first test statement below looks at mealcat at yr_rnd = 0 and the second test statement looks at mealcat at yr_rnd = 1.
data reg10; set elemapi2; if yr_rnd = 0 then yrrnd = -.5; if yr_rnd = 1 then yrrnd = .5; if mealcat = 1 then m1 = 2/3; if mealcat = 2 then m1 = -1/3; if mealcat = 3 then m1 = -1/3; if mealcat = 1 then m2 = -1/3; if mealcat = 2 then m2 = 2/3; if mealcat = 3 then m2 = -1/3; if yr_rnd = 0 then my11 = m1; else my11 = 0; if yr_rnd = 0 then my21 = m2; else my21 = 0; if yr_rnd = 1 then my12 = m1; else my12 = 0; if yr_rnd = 1 then my22 = m2; else my22 = 0; run;
proc reg data = reg10; model api00 = yrrnd my11 my21 my12 my22; test my11 = my21 = 0; test my12 = my22 = 0; run; quit;
The REG Procedure
Model: MODEL1
Dependent Variable: api00 api 2000
Parameter Estimates
Parameter Standard
Variable Label DF Estimate Error t Value Pr > |t|
Intercept Intercept 1 632.23557 5.80048 109.00 <.0001
yrrnd 1 -53.16321 11.60095 -4.58 <.0001
my11 1 288.19295 10.44284 27.60 <.0001
my21 1 123.78097 10.55185 11.73 <.0001
my12 1 247.42857 27.30218 9.06 <.0001
my22 1 105.53333 19.59588 5.39 <.0001
Test 1 Results for Dependent Variable api00
Mean
Source DF Square F Value Pr > F
Numerator 2 1951785 411.46 <.0001
Denominator 394 4743.51314
Test 2 Results for Dependent Variable api00
Mean
Source DF Square F Value Pr > F
Numerator 2 238079 50.19 <.0001
Denominator 394 4743.51314
We can also test the simple effects of mealcat at each level of yr_rnd via dummy coding. In SAS, each equal sign in the test statement equals one degree of freedom: because there are two equals signs in the second test statement, it is a two degree-of-freedom test, which is meant to do. The same logic holds true for the fourth test statement and this test is the simple effect of mealcat when yr_rnd=1.
data reg11; set elemapi2; m1 = 0; if mealcat = 1 then m1 = 1; m2 = 0; if mealcat = 2 then m2 = 1; m1y = m1*yr_rnd; m2y = m2*yr_rnd; run;
proc reg data = reg11; model api00 = m1 m2 yr_rnd m1y m2y; test m1 - m2 = 0; test m1 = m2 = 0; test m1 + m1y - m2 - m2y = 0; test m1 + m1y = m2 + m2y = 0; run; quit;
The REG Procedure
Model: MODEL1
Dependent Variable: api00 api 2000
Test 1 Results for Dependent Variable api00
Mean
Source DF Square F Value Pr > F
Numerator 1 1627262 343.05 <.0001
Denominator 394 4743.51314
Test 2 Results for Dependent Variable api00
Mean
Source DF Square F Value Pr > F
Numerator 2 1951785 411.46 <.0001
Denominator 394 4743.51314
Test 3 Results for Dependent Variable api00
Mean
Source DF Square F Value Pr > F
Numerator 1 96095 20.26 <.0001
Denominator 394 4743.51314
Test 4 Results for Dependent Variable api00
Mean
Source DF Square F Value Pr > F
Numerator 2 238079 50.19 <.0001
Denominator 394 4743.51314
For more information